数据统计与分析
By yangjh
Version: 0.8.2
研究的基本概念
什么是研究
广义的研究(research),就是为某一个目的而收集、分析信息(资料)的系统过程。
狭义的研究,指的是发现新知识 ,或者是对现有知识进行更深层次理解的活动。研究以发展一组有组织、架构与逻辑关系的知识系统为目标,或者说,研究的目的是发展出自己对于某个现象的观点(claims)或者理论(theory)。
研究方法(research method)就是收集资料的方法和分析资料的方法。
研究的三个要素

研究的分类
按研究目的分类:对综述现有知识的综述性研究(review research)、对某一领域进行初步研究的探索性研究(exploration research)、对自然、社会、人文现象进行总体描述的描述性研究(descriptive research)、寻求解释(因果关系)的解释性研究(explanatory research)。
除了上述四个常见目的之外,还有以预测事物、现象发展的预测性研究(prediction research),以及以发现或者建立新事物为目的的研究。
综述性研究案例
Reviewing the contributing factors and benefits of distributed collaboration
Distributed collaboration has become increasingly common across many domains, ranging from software development, to information processing, to the creative arts, to entertainment. At the time of writing, the adoption of Distributed Collaboration has thrust into the limelight as organizations across the globe are forced to work from home due to the COVID-19 pandemic. However, researchers have applied a myriad of terms to define these operations, we first addressed this issue by developing a definition of Distributed Collaboration which is representative of all its forms. Existing research has identified several factors that contribute to the success of Distributed Collaborations. Yet these factors are typically discussed in modular theoretical terms, meaning researchers and practitioners often struggle to identify and synthesize literature spanning multiple domains and perspectives. This research performs a systematic literature review to bring together core findings into one amalgamated model. This model categorizes the contributing factors for Distributed Collaboration along two axes (i) whether they are social or material (ii) whether they are endemic or relational. The relationships between factors is also explicitly discussed. The model further links these contributing factors to different collaborative outcomes, specifically mutual learning, relationship building, communication, task completion speed, access to skilled personnel, and cost savings.
探索性研究
探索性研究是一种所研究对象或问题进行初步了解,以获得初步印象和感性认识的,并为日后更为周密、深入的研究提供基础和方向的研究类型。使用这种类型的情况是:对某些研究问题,缺乏前人研究经验,对各变量之间的关系也不大清楚,又缺乏理论根据。属于这种研究类型的方式有多种,例如,参与观察、无结构式访问、查阅文献、分析个案等,常为小规模的研究活动。
探索性研究案例
《品牌信任结构维度的探索性研究》
品牌信任是消费品市场中建立和保持顾客忠诚的关键因素之一。本文在文献研究、深度访谈、焦点小组和问卷调查分析的基础上,得出消费者品牌信任的结构包含四个维度:品牌形象、质量水平、品牌认同度和企业价值观,并对企业的品牌管理决策提出了建议。
描述性研究
描述性研究对社会现象的状况、过程和特征进行客观准确的描述。进而揭示某种现象是什么,是如何发展的,特点和性质是什么。描述性研究的基本要求是对社会现象的描述应当达到描述的准确性和概括性的要求。
描述性研究很重要,在没有很强的假定的条件下,能做的只能是描述性研究。
描述性研究案例
《中国互联网络发展状况统计报告》
短视频用户规模达 8.88 亿,较 2020 年 12 月增长 1440 万,占网民整体的 87.8%。
解释性研究
解释性研究是关于现象或事物之间因果关系的研究。解释性研究是在描述性研究的基础上,进一步探寻“为什么”。解释性研究要在描述性研究的基础上对变量之间的关系进行分析,以确定它们之间是否存在相关,并进而判断它们之间是否存在因果关系。
在定量研究方法中,解释性研究通常是首先提出研究假设,然后从理论假设出发,设计出调查方案(收集资料的方案)并采用各种调查方法去收集经验材料,最后通过对资料的分析来验证假设,达到对社会现象进行理论解释的目的。
解释性研究案例
《媒介使用与社会资本积累:基于媒介效果视角》
社会资本是一种存在于人际交往关系中的经济资源,而媒介使用建构着人际传播的语境和互动行为,成为人际社会关系的建立、发展及维系过程中不可或缺的因素。本文以 CGSS(2015) 为样本,构建因果推断和中介效应模型,研究媒介使用对受众社会资本的影响。研究发现,传统大众媒介与新媒介的使用对受众社会资本积累具有显著影响,且随着媒介形态的不同而存在显著的结构性差异。其中报纸、杂志、广播、电视、互联网等单个媒介形态对受众社会资本积累的影响并不显著,仅仅是影响社会资本构成的某一个方面,电视和互联网媒介的使用甚至对社会化信任和互惠产生负向影响。媒介效果视角下,受众的媒介使用对其社会资本的影响,依赖于媒介所建构的阶层认同的中介效应。
预测性研究
预测性研究又称趋势研究,是在有关研究对象过去资料和数据的基础上建立某种预测模型,并在进一步的多次观察中证实该模型与实际情况的符合度。
预测性研究案例
《全面二孩”政策与义务教育战略规划——基于未来 20 年义务教育学龄人口的预测》
“全面二孩”政策的实施会影响未来我国义务教育学龄人口的变化。基于 2010 年全国第六次人口普查数据,对 2016—2035 年义务教育学生规模进行预测,并估算所需教师编制、教育经费和校舍建筑规模。研究表明,未来七年内我国小学学生规模不断缩小,初中学生规模由于第三次”婴儿潮”的作用有所增加;“全面二孩”政策对义务教育的影响将从 2022 年左右开始显现,并在短期内刺激义务教育学生规模迅速扩大,到 2030 年达到峰值,之后义务教育学生规模会重新开始缩小。对此波动,我国现有义务教育教师编制规模、教育经费投入力度和义务教育标准化建设速度基本可以应对,但应警惕快速城镇化带来的农村义务教育资源浪费和城镇义务教育承载能力不足等问题。建议谨慎对待农村撤点并校,同时加强教师队伍质量建设,并引导地方根据实际情况制定不同学段的教育战略规划。
以发现或者建立新事物为目的研究
《一种新型的锂离子电池正极材料》
介绍了 1 种新型的锂离子电池正极活性材料 LiFePO4 并解释了材料的结构特征和电化学过程。LiFePO4 具有较高的比容量和良好的循环稳定性等优良的电化学性能,但是目前还存在着制约容量释放的锂离子扩散系数小以及材料导电性能不太好等问题。在回顾该材料研究状态的基础上,说明了只要通过选取适当的制备工艺和进行合适的表面改性可以制备出具有优良电化学性能的 LiFePO4 粉体。这种粉体具有环境相容性、便宜以及资源丰富等诸多优点,是 1 种颇具潜力的锂离子电池正极替代材料。
按研究方法分类:质化研究、量化研究以及混合性研究。
按研究范式分类:实证主义范式、系统范式、阐释范式、批判范式。
按研究性质分类:基础研究、战略研究、应用研究。
研究的过程

测量
测量的基本概念
测量(measurement)是运用一套符号系统去描述某个被观察对象的某个属性(attribute)的过程。
测量就是按照一定的程序和规则,给物体的属性安排数字。
变异(variety)是统计的根本,有学者认为提出了社会科学研究的三个基本原则,认为变异性原则是其中首要的一个原则(谢宇,2012)。
变量与常数
变量(variable)表示某一属性因时间、地点、人、物不同而不同的内容。一个变量包括两个重要的概念,其一是所指涉的属性,就是变量的名称,其二是变量的数值。
随机变量(random variable)是指由随机实验结果来决定其取值的变量。它具有两个关键属性:随机性和变异性。
常量(constant),表示某一属性不因时间、地点、人、物不同而不同。
变量的分类
变量按照因果关系可分为自变量 (independent variable;IV)和因变量 (dependent variable;DV);
按照值是否连续,分为离散变量 (discrete variable)和连续变量 (continuous variable);
按照数值的意义,分为量化变量 (quantitative variable)和质性变量 (qualitative variable),把质性变量又叫做类别变量 (categorical variable)
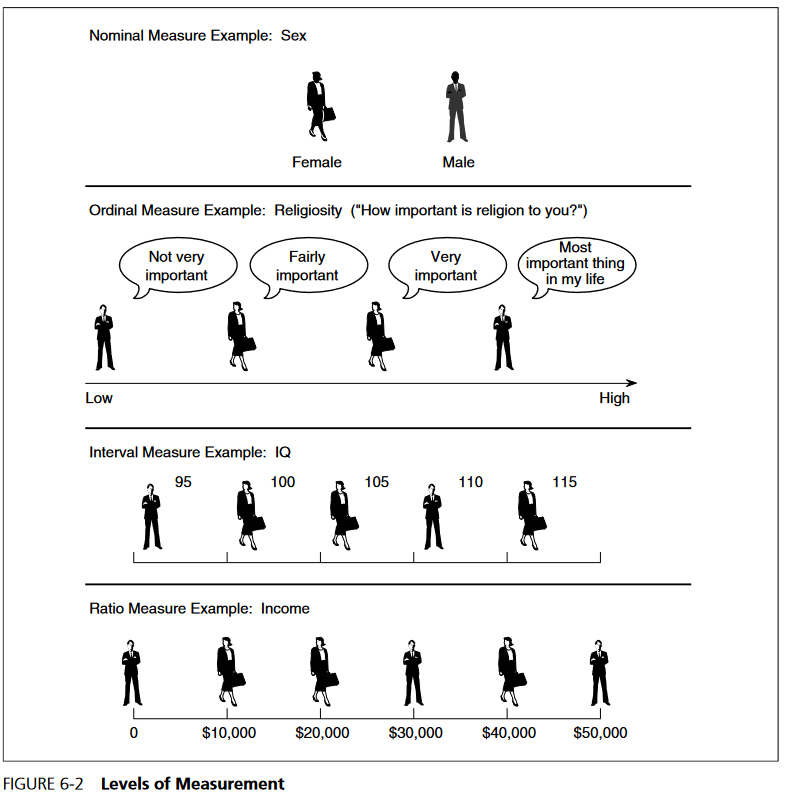
按照测量的层次,变量分为定类变量、定序变量、定距变量、定比变量。
测量层次
数据的性质决定测量所使用的尺度(scale)或层次(level)
定类尺度(nominal scale),用来评估所属种类。定类变量在测量时可采用互斥、穷尽原则提供选项。
定序尺度(ordinal scale),用来测量有顺序关系的类别。
定距尺度(interval scale),用来测定变量在某个属性上的程度特性。
定比尺度(ratio scale),是具有真正零点的定距尺度。
概念化与操作化
概念(concept)是我们赋予术语的一致含义,从而帮助沟通、测量和研究。概念在现实世界中并不存在,因此无法直接衡量。
概念化(conceptualization)是对抽象概念的精细化和具体化,是明确概念的的模糊心理意象。操作化(operationalization)是特定研究程序的发展,最终实现在真实世界中得到抽象概念的实证观察结果。
操作化是概念化的延伸,是我们如何识别现实世界中给定变量的不同属性的最终说明。
Conceptualization is the refinement and specification of abstract concepts, and operationalization is the development of specific research procedures (operations) that will result in empirical observations representing those concepts in the real world.
测量存在的一切
对于一个变量,通常存在多种测量变量的方式。如电视暴力就可通过武器的展示次数、武力使用次数等等方式进行测量。
如果一个概念存在,我们就可以测量它。
概念(concept)是“理念(conception)的家族树”,按照卡普兰的定义,概念是一种结构,是从你对它的概念、我们对它的概念以及所有使用过这个术语的人的概念中建构出来的概念。概念是不可能被直接观察到的,因为它是我们创造出来的。
概念源于精神意象(概念),它总结了看似相关的观察和经验的集合。尽管观察和经验是真实的,至少在主观上是真实的,但概念只是精神创造,是虚构的。
通常我们会陷入这样一个陷阱:相信术语具有真正的含义。当我们开始认真对待这些术语并试图精确地使用它们时,这种危险似乎会变得更加严重。
测量的步骤
- 概念化(Conceptualization)
- 语词定义(Nominal Definition)
- 操作化定义(Operational Definition)
- 在现实世界中测量(Measurements in the real world)
概念化(conceptualization)
Catherine Marshall 和 Gretchen Rossman
提出“概念漏斗”(Designing Qualitative
Research),通过这个漏斗,研究者的兴趣变得越来越集中。例如对同情心的普遍兴趣可以缩小到“关心他人福利的个人”,并进一步集中在“什么样的经验塑造了富有同情心的人的发展”。
指标和维度
概念化的产物,就是一个或多个指标(indicators),指标可表明我们正在研究的概念是否存在。
概念的特定方面用术语维度(dimensions)来表示:如我们可以说同情的“感觉维度”和同情的“行动维度”。概念的不同维度通常会为我们深入理解某个概念铺平道路。
概念化涉及到指定维度和标识各种指标。
指标的可互换性(interchangeability)
指标的可互换性意味着,如果几个不同的指标在某种程度上都代表着相同的概念,那么这几个指标在反映概念的行为方式上起着相同的作用。(如果它是真实的,并且可以被观察到。)
The interchangeability of indicators means that if several different indicators all represent, to some degree, the same concept, then all of them will behave the same way that the concept would behave if it were real and could be observed.
操作化
操作化的选择
对一个概念进行操作化,具有许多种选择。
变量范围(精度)
根据研究的需要和实际情况,研究人员需要确定某个变量的范围究竟设定在什么范围内合适。比如,你的研究中年龄范围是否要包括3岁以下的婴儿?人们对某个事物的态度,是否要简单归结为不喜欢、喜欢,还是从强烈反对到非常支持?
再比如,你只需要知道一个人是否已婚,或者不知道他或她是否从未结婚,或是单身、丧偶、离婚或再婚,会不会有什么不同?当然,对于这些问题没有一般的答案。答案来自于你的研究目的,或者你为什么要做一个特别的测量。不过,我们可以提到一个有用的指导方针。当你不确定要测量多少细节时,越细越好,而不是越粗越好。
概念的多个维度(意义)
一个概念,往往有多个维度。比如人们对不文明语言的态度,就有多个考察的维度:
- 人们在网络中对不文明语言的宽容程度如何?
- 人们在什么范围中能够容忍不文明语言的使用?
- 不文明语言在多大程度上被视为与同伴建立情感联系的手段?
- 不文明语言在多大程度上被视为人身攻击的工具?
在你的研究中,你必须清楚哪些维度是重要的。
测量水平(Levels of Measurements)
概念化和操作化的过程,可以看成是详述变量及其取值的过程。变量的取值必须穷尽及互斥。测量的水平或级别共有四种:定类(nominal)、定序(ordinal)、定距(interval)以及定比(ratio)
单个还是多个指标
有的概念,可以有多个指标进行测量。一些简单的概念,如年龄、性别、体重就能通过单个指标进行测量。一些复杂的概念,我们通常采用复合测量的办法,如通过平均绩点(GPA)来测量学生在学校期间的学习表现。
概念的定义和研究目的
我们知道,研究目的有描述和解释两种。其中概念的定义,对于以描述为目的的研究而言,具有非常重要的意义,因为概念的定义,决定了研究者描述研究的内容。例如:什么是暴力?不同的定义,对某一时段的电视节目而言,定义不同,则节目中包含的暴力内容的比例就不同。
反而对于以解释为研究目的的研究而言,核心概念的不同定义,不一定对概念之间关系有实质性影响。例如:不管新技术的定义为何,都不太会影响年轻人比老年人更容易接受新技术这样一个命题。
测量的信度与效度
信度与效度用来衡量测量一个变量的成功程度。
信度(reliability)
测量的信度,或者可靠度,是指使用特定的技术,反复测量同一个对象,每次是否会产生相同的结果。(在内容分析法中,信度就是指不同的编码员,对同一个内容是否会产生相同的编码。)对于信度,有一些基本的处理方法:
重测信度(Test-Retest Method)
有时,研究人员有条件进行多次相同的测量。如果您不希望信息发生变化,那么您应该期望两次得到相同的响应。这种一致性将证明足够的测试-重新测试可靠性。如果答案不同,测量方法可能不可靠。
通常,一个测量工具,必须经过重测,有高重测信度后,才可正式投入使用。
替代形式方法(Alternate-Form Method)
研究人员基于相同的测量项目池(the pool of measurement items),开发出两个版本的测量工具,使用两个不同的版本,测量同一组人,如果具有可接受的替代信度,则研究人员就对工具抱有信心。
内部一致性方法(Internal Consistency Method)
这项技术,基于这样一个假设:在一个给定的测量中,不同的指标之间应该相互相关,换句话说,他们应该表现得始终如一。内部一致性方法可以有几种形式。
半可靠性(split-half reliability)
假设你已经创建了一个问卷,其中包含十个你认为可以衡量浪漫爱情的项目。使用半分割技术,随机将这十个项目分配给两组五个项目。每一组都应该提供衡量浪漫爱情的标准,并且每一组都应该以他们对调查对象的分类方式做出回应。这两部分之间的相关性很高,则可靠性高。
项目总可靠性(item-total reliability)
此技术将度量中每个项的一致性或相关性与度量中所有项的总分进行比较。当一个度量具有较高的项目总可靠性时,它意味着它的组件项与所有项目的总分正相关。如果一个给定的项目与总分没有很好的相关性,那么它的表现就不可靠,应该从度量中去掉。
使用已有量表(Using Established Measures)
采用广泛采用的量表,尤其是已经被证明具有高可靠性的量表,也是确保测量信度的方法之一。但需要注意,随着社会的变化,一些年代过久的工具,可能需要进行根本性的修订。
研究者的可靠性
研究者(访问员、编码员)的可靠性也会产生测量不可靠的问题。有几种解决方案,如:调查主管回访、多个编码员独立编码。
信度系数(Reliability Coefficients)
信度系数用来描述一致性的程度。信度系数有多种:相关系数r、K-R 20、克朗巴赫的α;科恩的kappa。这些系数的值从0到1,表示一致性的程度。
信度系数至少应该不小于0.7。
效度(Validity)
测量有效性指的是测量充分反映概念真正意义的程度。
内容有效性
内容有效性(content validity)指的是一次测量,在多大程度上涵盖了概念中包含的意义范围或维度。也就是说,对概念的测量,要在周延的维度上进行。比如,测量数学计算能力,就不应该仅仅测量加法,其它运算都应该测量。
第一种解决内容有效性的方法是表面效度(face validity),指的是测量是否与我们关于某个概念的心理图像相抵触。例如:工人在图书馆的借阅数量感觉上与工人的工作士气没有多少关联,但是向工会提出申诉的数量,就可视为工作士气的一部分。
第二种解决有效性的方法是专家组有效性(expert panel validity),指的是有该领域的一组专家评估一项测量的有效性。
第三种解决有效性的方法是用过因素分析(factor analysis),因子分析可用于分析测量的多维结构。通过确定哪些项目在人们的头脑中似乎是组合在一起的,进而证明测量的有效性。例如:Kathleen Ellis的研究
标准效度(Criterion Validity)
第二种主要的效度形式是标准效度,它分为预测效度(predictive validity)和并行效度(concurrent validity)两种形式。这两种形式的共同点是通过一个度量与某个外部标准的关系来评估它的有效性。为了预测有效性,一个度量必须证明它可以预测未来的行为。
建构效度(Construct Validity)
建构效度,是基于变量之间的逻辑关系。在判别结构效度中,测量的变量与理论上不同变量的度量存在偏离或负相关。例如,假设您想研究婚姻满意度的来源和后果。作为研究的一部分,您开发了一个婚姻满意度的度量标准,并希望评估其有效性。除了制定衡量标准之外,您还将对可变婚姻满意度与其他变量之间的关系产生一定的理论预期。如果这些理论预期存在,则建构效度高。
谁来决定有效性?
研究者有时会互相批评,因为他们暗地里认为自己比他人更优秀。那谁来决定有效性呢?研究者应将同行和研究参与者视为对他们所研究概念最有用的意义和测量方法达成一致的来源。
信度与效度的关系
信度与效度之间存在一种张力。概念操作化时的名义定义以及度量规范似乎剥夺了这些概念的丰富意义,也就是说,在某种程度上,对可靠性的追求,使得概念的丰富内涵受到限制,产生测量效度下降的问题。指定具体、可靠的测量措施往往会削弱我们理解中的概念的丰富意义,这是不可避免的。最好的解决方案是尽可能周延概念的不同维度。
给任何概念赋予特定含义的唯一理由是效用,应该以帮助我们了解周围世界的方式来测量概念。
问卷设计
问卷结构
问卷由封面信、指导语和题项构成。
封面信
封面信需要告知被调查对象如下内容:调查者身份、调查内容、调查目的、调查对象的选取方法、对调查结果的保密措施。
调查者身份必须要写明单位、组织,最好附上单位地址、电话号码、负责人姓名。不要只写“xx调查组”、“xx课题组”。
用一句话介绍调查内容,不要过于详细。
我们正在我市市民中进行方言传承的调查
这次调查主要希望了解我校同学对阅读方式的看法
通常情况下不能欺骗受访者,直接告诉调查目的,也不要仅仅抽象地说明调查目的,尽量说明调查对于被调查者的实际意义。
我们这次调查时要摸清目前图书市场定价的现状和存在的问题,以便为今后的图书定价改革的有关政策提供科学依据,进一步提升广大读者的图书消费满意度
需要简要说明调查对象的选取方法(科学的随机抽样),以便消除被调查者“为什么会选中我接收调查”这样的疑惑。
需要强调对调查结果将会采取何种保密措施,以消除被调查者的不安全感。
我们按照科学的随机抽样方法选择了一部分同学作为全校学生的代表,您是其中一位,本次调查以不记名的方式进行,不用填写您的姓名和单位,问卷中的答案无对错之分,而且每份问卷的填写结果将根据国家统计法予以绝对保密,最终数据将仅仅以统计结果方式呈现。
问卷指导语
指导语用来说明填答方式
请根据自己的实际情况在合适的答案上画圈或在空白处直接填写
问卷提交方法说明
问卷的题项
问卷的题项(items),包括问题和答案。
问题有封闭式问题(closed-ended question)和开放式问题(open-ended question)。
问卷中尽量采用封闭式问题,以便于编码和进行统计分析。
开放式问题如何处理?方法之一是采用扎根理论分析(Grounded theory analysis),实际上采用量化思路,进行编码,将其转化为封闭式问题的题项,再进行统计分析。
题项编排顺序
- 甄别问题,用来筛选合乎条件的被访者(可采用迂回方式,间接询问,以达到甄别目的,如“你是研究生吗”可采用“你的学历:本科、硕士、博士”这样的方式)
- 预备问题,使被访者开始适应访问
- 简单问题,简单询问行为,为过渡到复杂问题奠定基础
- 复杂问题,询问态度,难于回答及复杂的问题
- 最后部分,收集个人信息等背景资料,结束语
问卷题项编排顺序的经验性建议
- 首先询问关于受访者行为方面的问题
- 其次询问关于受访者态度方面的问题。
- 最后询问关于受访者个人情况方面的问题。
问卷设计流程
问卷设计的流程如下:
- 确定调查主题、提出研究问题
- 形成理论假设并进行概念操作化,提出研究假设
- 根据操作化方案中的测量指标设计对应的问题
- 按照合适的顺序编排问题,形成问卷初稿
- 对问卷初稿进行与测试或专家评价,并加以修订
预测试需要注意的要点
- 有效回收率是否过低。有效回收率是指回收问卷中除废卷以外的问卷所占比例,反映问卷设计的总体情况。
- 填答内容是否存在错误,若有错误,可能是题项存在歧义
- 填答方式出错,对问题填答要求的不理解或误解而导致的错误,反映问卷指导语或题项的问题形式存在缺陷。
- 填答不完全。问卷中的部分问题未做填答,反映问卷题项中的问题设计存在缺陷。
问卷设计的注意事项
- 题项中的问题应当是表达明确无歧义的
- 题项中的问题应当是包含单一含义
- 题项中的问题应当避免使用诱导性问题
- 题项中的问题避免使用否定式问题
- 题项中的问题应当充分考虑调查对象的理解能力
- 题项中的问题应当充分考虑调查对象的记忆能力(如最近1周的平均值)
- 题项的答案应在逻辑上是周延的。
问卷设计的建议
- 问卷的数量以填答时间控制在20分钟内为宜。
- 每个题项的性质(单选或多选)最好做出明确标识。
- 多项选择题编码难度较大,尽量少用。
- 关联式问题同样会增大编码难度,尽量少用。
- 排序问题可能会导致填答困难,尽量少用。
- 隐私或敏感问题应当问的委婉或尽量不问。
- 询问态度的问题的答案数量一般为5个,最好为奇数且不超过7个。
统计分析基础理论
总体和样本
总体是特定研究中所关注的所有个体的集合。没有总体就不需要做统计。
样本是指那些从总体中选出的个体,通常在研究中被用来代表总体。
参数值与统计值
参数值是描述总体的数值。
统计值是描述样本的数值。
抽样
抽样(Sampling)抽样就是从研究总体中选取一部分代表性样本的方法。
抽样的方法可分为随机抽样和非随机抽样。随机抽样指的是从总体中抽取样本时,总体中的每一个元素都有同等的几率被选中。
随机抽样分为:简单随机抽样、系统抽样、分层抽样、整群抽样、多阶段抽样+PPS 抽样。
非随机抽样可分为:偶遇(便利)抽样、判断(立意)抽样、配额抽样和滚雪球抽样。
抽样误差
抽样误差是一种差异,指存在于样本统计值和总体参数值之间的误差。
抽样误差通常是由两部分构成:
- 随机抽样误差:这是由于随机性抽取样本而引起的误差,即使在相同总体下,不同样本也可能产生不同的统计值。
- 系统性误差:这种误差是由于抽样方法或调查设计中的偏差引起的,这可能会导致样本结果偏离总体参数。
抽样误差不仅由样本间的随机差异构成,还包括可能由于抽样方法或设计错误引入的系统性偏差。
统计方法的分类
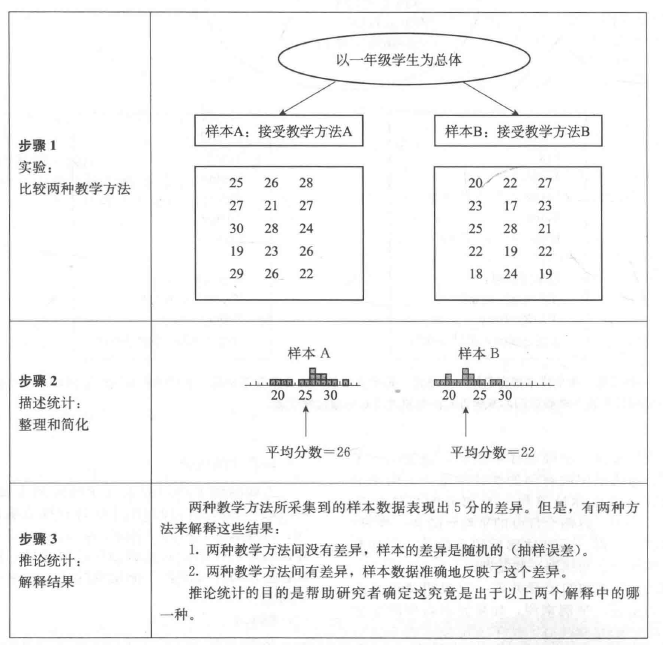
描述统计(Description Statistics)
描述统计是用来总结、整理和简化资料的方法。例如用平均数表示总体的特征(年龄、家庭规模等等)。
推论统计(Inferential Statistics)
推论统计包括能够用于研究样本对并样本所来自的总体做出推论的技术。推论统计的目的是帮助研究者确定差异是由抽样误差引起的,还是由于系统性的原因(自变量)引起的。
定性分析在描述变异的现象时是不可靠的,因为不知道个案的代表性。
相关性
所谓相关,是指一个变量的变化与另一个变量的变化有连带性。
如教育水平和人生志愿、性别和内容消费行为的偏好等等。
相关的强度与方向
大多数的统计方法是以 0 代表无相关,以 1 代表完全相关。不同测量层次有着不同的相关系数。
| 相关系数 | 关联程度 |
|---|---|
| 0.10 以下 | 微弱相关或无相关 |
| [0.11-0.39] | 低度相关 |
| [0.40-0.69] | 中度相关 |
| [0.70-0.99] | 高度相关 |
| 1 | 完全相关 |
相关还有方向的区分,如正相关表示一个变量增加时,另外一个变量也在增加。
因果关系的三个条件
相关的两个变量,不一定有因果关系,可能是共同变化。
保罗·拉扎斯菲尔德提出了两个变量存在因果关系的三个条件:
- 原因出现在结果之前;
- 变量之间存在相关关系;
- 两个变量之间的相关性不能被与这两个变量都相关的第三个或更多变量所解释。
还有学者提出如下条件:
- 存在事件的时间顺序,原因事件在结果事件之前。这称之为时间优先(temporal precedence)。
- 原因事件呈现时,结果事件发生。原因事件不呈现时,结果事件不发生。这称之为原因与结果的协变化(covariation of cause and effect)。
- 除了原因变量外,没有其他因素能够是观察到的结果的原因。这称之为排除备择解释(alternative explanations)。
因果关系的方向性
我们更容易研究原因的结果(effects of causes),而不是结果的原因(causes of effecs)。我们能做的就是解释有了特别的原因会有什么样的结果。
研究结果的原因(“causes of effects”)也很重要,但它们通常更难以确定,因为通常涉及到更多复杂的因素和潜在的原因链条。因此,我们在研究中更常见的是关注原因的结果(“effects of causes”),以便更好地了解因果关系。
抽样分布
抽样分布(Sampling Distribution)是指从总体中随机抽取多个样本,并计算每个样本的统计量(如平均值、标准差、比例等)后,将这些统计量组成的分布。抽样分布提供了有关样本统计量的概率性质和变异性的信息,它对于统计推断和假设检验非常重要。
离散变量的抽样分布
离散变量的概率分布类型有二点分布、二项分布、超几何分布、泊松分布等。
连续变量的抽样分布
有均匀分布、指数分布、正态分布等。
推论统计
对样本资料进行描述统计后,我们还要根据样本的研究结果来推测总体的情况。
以样本的数值来推算总体,结论可能正确,也可能错误,而运用概率论原理,我们可以求出推论统计犯错的可能性大小。
只要我们是采用随机抽样方法,就可以根据抽样分布,以样本的数值来推测总体的情况。
推论统计的分类
推论统计一般分为两大类:参数估计(parameter estimation)和假设检验(hypothesis testing)。
参数估计是根据随机样本的统计值来估计总体的参数值。
假设检验是先提出假设总体的情况,再以随机样本的统计值来检验这个假设是否正确。
社会研究大多数采用假设检验的推论统计分析方法。
因果关系总是概率性的,比如吸烟会导致癌症,但并不是说每个人吸烟都会导致癌症。
假设检验基础知识
研究假设与虚无假设
否定域与显著度
\(p\) 值
效应量
单侧与双侧检验
独立样本与相关样本
两种误差
参数与非参数检验法
假设检验的步骤
研究假设与虚无假设
科学研究一般是先成立假设,即假设总体中存在某种情况,这个假设,称为研究假设(research hypothesis),简写为\(H_1\)。
例如:
\(H_1\):媒介评价正向影响媒介参与意向。
与研究假设相对立的假设,在统计学上称为虚无假设(null hypothesis),简写为\(H_0\)。
例如:
\(H_0\):媒介评价与媒介参与意向不相关。
在推论统计分析中,我们总是要做假设,所以理论是非常重要的,没有理论就没有假设。理论需要逻辑思维和经验积累。
虚无假设的检验
如果在样本中发现两个变量存在相关,固然存在总体的情况确实如此,但也可能是由于抽样误差或者偶然引起的。
假设检验的基本原则是直接检验\(H_0\),从而间接地检验\(H_1\),目的是排除抽样误差的可能性。
如果我们能证明\(H_0\)对的可能性很小,那么就认为\(H_1\)“可能”是对的。
否定域与显著度
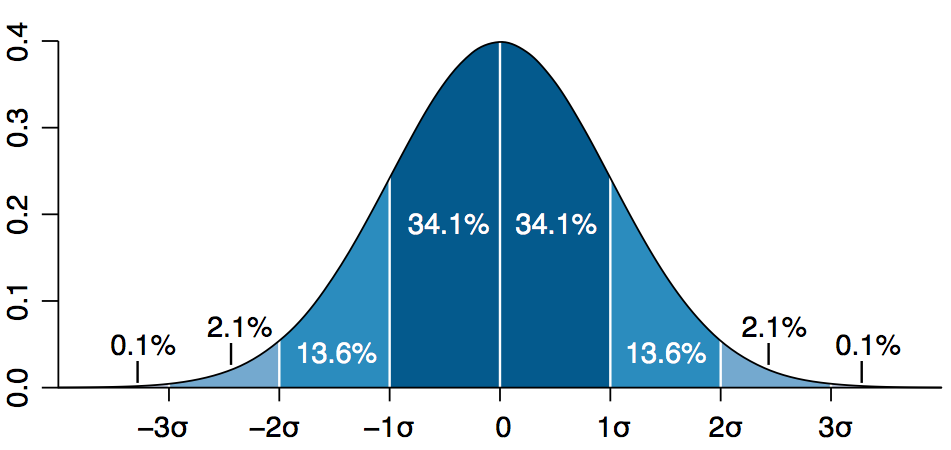
否定域就是抽样分布中一端或两端的小区域,如果样本的统计值在此区域范围内,则否定虚无假设。显著度(level of significance)表示否定域在整个抽样分布中所占的比例。
\(p\) 值
在实际研究中,假设虚无假设正确时,利用观测数据得到与虚无假设相一致结果的概率称为 \(p\) 值(p-value),也叫概率值、概值。
\(p\) 值并不是虚无假设正确的概率,而是指假如虚无假设正确的话,样本观测结果在抽样分布中可能发生的概率。
显著性水平 \(α\) 和 \(p\) 值的关系在于,显著性水平 \(α\) 是研究者假定的理论值,而 \(p\) 值是利用样本计算得出的实际值。
随着 \(p\) 值的减少,结论的可靠性越来越强,在社会科学研究中,通常把 \(p\)≤0.05 作为显著水平的标准。但实际上,“显著”与“不显著”之间是没有清楚界限的。
效应量
针对虚无假设检验存在的不足,一些国际期刊要求在报告检验结果的同时还要报告效应量 (effect size)。
效应量(effect size):一种度量效应大小的指标。如果把 \(p\) 值理解为统计显著性 (statistical significance),统计效力就是现实显著性(practical significance)。\(p\) 值代表的是统计学上的意义,而效应量是能反映实际上的意义,有时候即使有显著的统计学意义,但是效应量却可以很小。
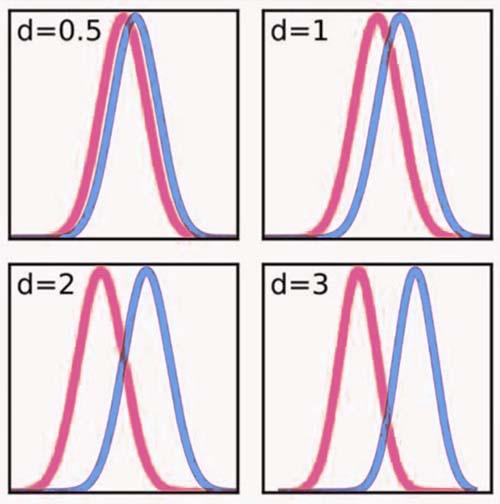
效应量并不是唯一的参数,也就是说有很多指标都可以用来表示效应量。学界对于效应量的定义是比较宽松的。凡是研究者感兴趣的量都可以是效应量。

单侧与双侧检验
否定域只在一端,称为单侧检验(one-tailed test),如果否定域在两端的位置,称为双侧检验(two-tailed test)。
研究假设的方向决定选择单侧还是双侧。
\(H_1\):媒介评价正向影响媒介参与意向。
选择单侧检验。
\(H_1\):关注海外媒介和网络新闻对媒介参与意向有何影响?
选择双侧检验。
单侧检验仅考虑单方向的差异性,因此在同样的显著水平下,可以较双侧检验更容易得到显著结果,统计检验力(power)大于双侧检验,因此采用单侧检验对于研究者较为有利。但是,采用单侧检验必须提出支持证据(文献或逻辑),否则需采用双侧检验。
独立样本、配对样本、单样本
配对是同一批样本的前后比较,独立是两批不同样本的的比较。对比两个来自不同样本的平均值差异时,需要依情况选择独立样本\(t\)检验还是配对样本\(t\)检验。
单样本是指样本只来自某次独立的抽样。单样本的推论检验主要研究样本是否服从正态分布、均匀分布、指数分布以及泊松分布等。
两种类型的错误
用样本的值推测总体,不管是否接受研究假设,都存在犯错的可能。
第一类错误(type Ⅰ error),是指否定\(H_0\),但实际上\(H_0\)是对的。第一类错误的可能性就是显著度。通常我们把犯这种错误的概率记为 α。
第二类错误(type Ⅱ error),是指不否定\(H_0\),但实际上\(H_0\)是错的。通常我们把犯这种错误的概率记为 β。
第一类错误和第二类错误是相对立的,要消除两种误差的矛盾是不可能的。但增大样本量,可在一定程度上同时减少两者的可能性。

假设检验的两种方法
假设检验的方法可以分为两大类:参数检验法及非参数检验法。参数检验法原则上在假设检验时,犯第二类错误的可能性小于非参数检验法。
参数检验法要求总体具备某些条件,如正态分布或者标准差相等。
非参数检验法,不要求总体数值具备特殊的条件。但当样本量足够大时,非参数检验法的检验力也是很有保证的。
假设检验的步骤
- 确定研究假设和虚无假设;
- 选择适当的检验统计方法;
- 确定抽样分布;
- 决定显著度(在社会科学中,\(α\) 一般取 0.05、0.01、0.001),根据研究假设选择单侧还是双侧;
- 计算出 \(p\) 值;
- 根据计算结果,作出决策(如果 \(p\) 值小于或等于 \(α\),则否定虚无假设;反之则不否定虚无假设)。
在研究报告中,需要汇报研究假设、显著度和单侧或双侧检验。
看见统计
统计学基本概念可视化: https://yangjh.gitee.io/seeing-theory
统计学虽然不完美,但却是社会科学刻画异质性唯一可靠的工具(谢宇,2012)。
数据预处理
数据编码
在量表或者问卷中,通常情况下,我们使用1代表A,2代表B,依次类推。
当我们遇到的选项内容如果为数字开头时,如2000-3000 元时,需要使用合适的值内容,建议使用中文而非数字表示该项内容,以免在输入时产生不必要的错误。
在 SPSS 中录入数据
在 SPSS
中,有两个界面:数据视图和变量视图,定义变量在变量视图中进行。
题项 = 指标 = 变量
- 变量类型和长度。在 SPSS
中定义变量类型和长度的对话框是同一个。其中长度(width)指的是变量的长度,如
width=5,表示长度为 5,Decimal 表示小数点后的位数。 - 变量的标签(label)用来说明变量名称,允许变量标签字符数最多可达 256 个。当为变量定义了变量标签之后,在进行分析时,对话框中的待选变量列表框和分析变量列表框中的变量名前标注有变量标签,操作时一目了然。
- 变量的赋值(value)实际就是题项中的答案编码,如果为填空题,value 值就为空。给变量值赋予值标签后,可以使输出结果更清楚,更便于阅读和理解。
- 缺失值(missing values)的定义,在 SPSS
中有三种情况:第一种是默认缺失值。即没有输入值时,SPSS
不作任何处理,空值。第二种是设置三个缺失值,如
97、98、99。如果输入值为97、98、99,则会被处理为缺失值。当我们使用随机抽样时,不能随意丢弃个案,否则会对总体随机性产生影响。第三种是定义缺失值的范围(这样就可以定义多个缺失值),再加上一个离散缺失值。 - 测量层次必须设置准确。在 SPSS 中有三个层次,定比、定序、定类。
数据清理
数据清理的目的是以高质量的数据保证数据分析的有效性,进而保证研究的高质量。
数据清理,可从这样三个方面进行:
核查变量测量层次
对每个变量的测量层次进行核查,设置正确的层次。
在 Python 中可通过 astype() 函数设定变量类型。
from pandas.api.types import CategoricalDtype
df_demo['性别'] = df_demo. 性别.astype(CategoricalDtype(['男性','女性'], ordered=False))
df_demo['年级'] = df_demo. 年级.astype(CategoricalDtype(['大一','大二','大三','大四'], ordered=True))
df_demo['日期'] = df_demo. 日期.astype('datetime64[ns]')在 SPSS
中,可在变量视图中的测量栏,指定变量的层次。
删除空白、重复数据
Python 中删除空白数据、标记重复数据
SPSS 中删除空白数据、标记重复数据
空白数据直接在数据视图中删除。
重复数据的标记可通过数据菜单中的标识重复个案模块来完成。
检查值范围与逻辑一致性
从可能性检查(wild code checking)和逻辑性检查(logical checking)两个方面着手:
可能性检查是检查变量的取值中是否有超过范围的数值。
SPSS
可通过描述统计中的次数分布或者值的排序完成。Python
中对类型变量可以通过浏览类型的值进行查看。
逻辑性检查是通过多个变量组成的逻辑条件来判断数据是否符合要求。
在 SPSS
中通过数据菜单中的选择个案模块中的如果条件满足对话框来筛选。
Python 可通过设置筛选条件,来进行逻辑一致性检验。例如:
数据转换
为了分析的需要,有时我们需要对单个或多个数据进行计算、转换。
在 SPSS
中,可以通过转换菜单中的计算变量、重新编码等功能实现数据转换。
在 Python
中,可以通过自定义函数和apply()方法结合来达到上述目的。对于定类、定序变量,可使用其编码进行数值运算。
单变量统计分析
单个变量的描述统计
单变量的描述统计较为简单,只需注意测量层次即可。
单变量的描述,可从频数分布、集中趋势、变异性来描述总结一系列数据。
平均值
平均值(mean),是所有数据总和除以数据的数目,有时也被简单称为“均值”。
\[ \bar{x} = \frac{\sum x_i}{n} \]
平均值在数学上之所以叫期望值(expected value),是因为均值可以看成是从手上的数据中随便抽取一个时,用来代表这个未知数字的“一般性误差最小”的代表,也就是说用平均数猜测时的数值与真实值差异一般最小。
方差
方差(variance)表示所有数据离开平均值的距离除以数据的数量。用来描述一组数据的分散或集中程度。方差越大,集中程度越低。
\[\sigma^2 = \sum{\frac{(x_i-\bar{x})^2}{n}}\]
因为方差的单位也会被平方,为了更好的理解数据,统计学家将方差的平方根,称为标准差:
\[\sigma = \sqrt{\sum{\frac{(x_i-\bar{x})^2}{n}}} \]
标准化
为了对比不同单位的数据,如单位为厘米的身高和单位为英寸的身高,统计上一般都会把一个变量的一组观测值的平均值转化为 0,标准差转化为 1。
两个变量之间的关系不会因为任何的线性转换而改变的。线性转换的意思是转换函数只有一阶。
把一个变量的平均值变为 0,标准差变为 1,就是一个线性转换,这个转换在统计上称为标准化(standardization),转化后的值称为标准值(standard scores,or z-score)。转换公式为:
\[z = \frac{x-\bar{x}}{\sigma}\]
标准化后的值,相当于用一个新的尺子来测量,这把尺子的单位是原始数据的标准差。
SPSS 中的单变量描述统计
选择分析菜单中的描述统计,然后根据变量测量层次,设置合适的统计方法即可。
如要计算平均值的置信区间,可选择“分析”—“描述统计”—“探索”项。
Python 中的单变量描述统计
通过value_counts()方法和describe()实现。
以 APA 格式撰写结果
对 300 名消费者进行调查,单次消费金额为 109.90 元(SD=33.67),均值 95%置信区间为 [96.23,121.37]。
多选题的统计
- 多选题在 SPSS 中,无法直接处理,需要先定义,才能进行描述统计。
- 选择
分析菜单中的多重响应即可完成。 - 通常选择
定义变量集中的二分法编码方式。 - 分析结果最好在其他软件(如 Excel)中排序。
排序题的统计
- 排序题与多选题处理类似,但稍微复杂一些。
- 在编码时:没有被选择的选项,编码为 0,被排序的选项,编码为 1、2、3 等等。
- 选择二分法编码,但是编码值不再只有 0 和 1 两个值。
- 有几个排序,则新建几个多选题变量,而不是只有一个变量。
单变量推论统计
单样本 \(t\) 检验是一种统计学上的假设检验,用于确定未知的总体均值是否与特定的值有差异。可以对连续型数据使用该检验。数据来自呈正态分布的总体的随机样本。
\(t\) 检验的前提条件:
- 数据值是独立的。
- 测量值是连续型的。
- 样本是随机抽取的。
- 样本规模较大。
单样本 \(t\) 检验案例
假设我们从多家不同的商店中收集了 31 根能量棒的随机样本,以此来代表一般消费者可以获取的能量棒的总体。能量棒的标签标明每根能量棒含有 20 克蛋白质。
\(H_1\):标签上写着的蛋白质为 20 克是不正确的,潜在的总体均值不等于 20。
\(H_0\):标签上写着的蛋白质为 20 克是正确的,潜在的总体均值等于 20。
单样本 \(t\) 检验在 SPSS 中的实现
操作步骤:
- 选择
分析菜单中的比较平均值,选择单样本 t 检验. - 在出现的对话框中,在
检验值中填入20,单击确定。
结果解读:
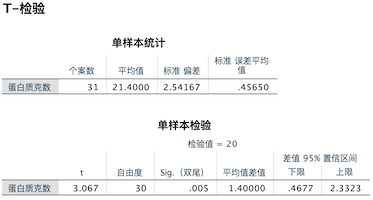
双侧检验的 \(p\) 值是 0.005。这个 \(p\) 值描述了当潜在总体均值实际上是 20 时,我们看到样本平均值像 21.4 这么极端或者更极端的可能性;换句话说,也就是与我们在样本中观测到的均值相比,观测到某个样本均值与 20 之间存在差异(甚至存在更大差异)的概率。\(p\) 值是 0.005 意味着在 1000 次中大约有 5 次机会。我们可以充满信心地拒绝总体均值等于 20 这个原假设。
使用 Python 进行单样本 \(t\) 检验
还是以上面的案例数据进行分析:
# 导入分析工具
import pandas
import scipy
from scipy.stats import ttest_1samp
# 读取数据文件
sample = pandas.read_spss(f'../data/one-sample-t-test.sav')
# 进行单样本 t 检验
(t, p) = ttest_1samp(sample, popmean=20)
# 打印结果
print(t, p)结果的解读,同上。
单样本 \(t\) 检验的效应量
效应量可以使用 Cohen 的 \(d\) 值:计算公式有两个:
\[ d = \frac{|样本均值-检验值|}{标准差} \] \[ d = \frac{t}{\sqrt{样本数}} \]
依据 J.Cohen(1988) 的经验法则,\(d\) 值的小、中、大效应量分别是 0.20, 0.50, 0.80。
| \(d\) 值 | 关联程度 |
|---|---|
| \(d\)<0.20 | 效应量非常小,几乎等于 0 |
| 0.20≤\(d\)<0.50 | 小效应量 |
| 0.50≤\(d\)<0.80 | 中度效应量 |
| \(d\)≥0.80 | 大的效应量 |
以 APA 格式撰写单样本 \(t\) 检验结果
研究者以某地 300 名学生实施测验(调查),并进行单样本\(t\)检验,样本的平均值为 25.20(\(SD\)=9.19),95%置信区间为 [20,90,29.50],与 20 分有显著差异,而且比 20 分高,\(t\)(19)=2.53,\(p\)=0.02,效应量\(d\)=0.57。
双变量统计分析
相关系数的选择标准
表示两个变量之间关系的相关系数有很多种,选择相关系数的标准之一是统计值的意义。最好选用统计值有意义的相关测量法,在统计学中有一组相关测量法的统计值具有消除误差比例(proportionate reduction in error)的意义,称为 PRE 测量法。选择相关系数的另一个标准是两变量之间的关系是对称或不对称关系。还有一个标准是两个变量的测量层次。
什么是消除误差比例呢,PRE 数值的意义,就是表示用一个变量来解释另一个变量时,能够减除百分之几的错误。
根据变量测量层次的不同,有不同的统计方法,下面按照不同的变量组合逐一进行说明:
定类与定类
两个定类变量之间的关系,可以通过交互分类表(cross-tabulation)进行分析。
所谓交互分类,就是同时依据两个变量的值,将所研究的个案分类。
通常用列联表进行交互分类。

交互分类表格中下方的总次数,称为边缘次数(marginal frequencies),表中的其他次数,称为条件次数。
列联表的设置
通常我们将自变量放在列,因变量放在行。
为能相互比较,应使用百分比使其标准化。
以自变量作为计算百分率的方向。

交互分类表的实现
在 SPSS
中使用分析菜单中的描述统计中的交互表即可绘制交互分类表。
在 Python 中的实现:
定类与定类变量之间的相关系数
如果两个变量都属于定类测量层次,可用 Lambda 相关测量法,也可用古德曼和古鲁斯卡的 tau-y 相关测量法。
Lambda 相关测量法,其基本逻辑是计算以一个定类变量的值来预测另一个变量的值时,如果以众值作为预测的准则,可以减少多少误差。
Lambda 相关测量法有两种形式,一种是对称形式,简写 \(λ\) 系数。另外一种是不对称形式,简写 \(λ_y\) 系数。
tau-y 相关测量法是不对称相关测量法,系数值具有消除误差比例的意义。
tau-y 在计算时考虑全部的次数,故其敏感度高于 Lambda 相关测量法。
Lambda 与 tau-y 在 SPSS 中的实现过程
定序与定序
如果两个变量都属于定序测量层次,可用古德曼和古鲁斯卡的 Gamma 系数,也可用萨莫司的 \(d_y\) 系数。
基本逻辑是根据任何两个个案在某变量上的等级来预测它们在另一个变量上的等级时,可以减少的误差是多少。
Gamma 系数是对称相关测量法,如果我们认为相关不对称,则最好采用适用于不对称关系的萨莫司 \(d_y\) 系数。
Gamma 与\(d_y\)系数的 SPSS 实现过程
定距与定距
如果两个变量都属于定距测量层次,可用线性回归分析法以自变量的数值预测因变量的值,用皮尔逊(Pearson)的积矩相关系数(简写为 \(r\))来测量两个变量的相关程度和方向,还可用回归系数 \(b\) 表示。
\(r\) 系数与简单线性回归分析都是假定 \(X\) 与 \(Y\) 的关系具有直线的性质,因此,在使用这两种方法之前,最好通过散点图观察变量的分布状况。
如果观察到近似线性分布,则先计算 \(r\) 系数,如果 \(r\) 系数值相当大,就可用简单线性回归法来预测数值。如果 \(r\) 系数比较小,就不要用线性回归法做预测。
在 SPSS 中制作散点图
\(r\) 积矩相关系数
\(r\) 系数假定两个变量的关系是对称的,即不区分自变量和因变量。其值在 [-1,1] 之间。\(r^2\) 称为决定系数(coefficient of determination)。\(r^2\) 具有消除误差的意义。
| 相对系数绝对值 | 决定系数 | 关联程度 |
|---|---|---|
| \(r\)<0.25 | \(r^2\)<0.06 | 微弱相关或不相关 |
| 0.25≤\(r\)≤0.5 | 0.06≤\(r^2\)≤0.25 | 低度相关 |
| 0.5≤\(r\)≤0.75 | 0.25≤\(r^2\)≤0.56 | 中度相关 |
| \(r\)>0.75 | \(r^2\)>0.56 | 高度相关 |
\(r\) 系数的 SPSS 实现过程
回归系数 \(b\) 的 SPSS 实现过程
简单线性回归方程式为 \(Y=bX+a\),
\(b\) 值,也称为回归系数,表示自变量对因变量影响的大小和方向。它是一个分析不对称关系的统计方法。
\(a\) 表示截距。
https://www.bilibili.com/video/BV1kf4y1B7DN/
上面的演示中,得出:\(家务劳动时间=-0.83 教育年期+5.33\)。下载演示数据文件
定类与定距
定类与定距的相关性,可采用 eta 平方系数(\(\eta^2\)),又叫相关比率(correlation ratio),进行描述,\(\eta^2\) 是以一个定类变量的值来估计一个定距变量的均值。\(\eta^2\) 具有消减误差比例的意义。
| \(\eta^2\) | 关联程度 |
|---|---|
| 小于 0.01 | 微弱相关或不相关 |
| [0.01-0.06] | 低度相关 |
| [0.06-0.14] | 中度相关 |
| [0.14-0.99] | 高度相关 |
| 1 | 完全相关 |
参考资料:
Miles, J., & Shevlin, M. (2000). Applying Regression and Correlation: A Guide for Students and Researchers. SAGE.
eta 平方系数的 SPSS 实现过程
定类与定序
由于定序测量层次具有定类测量层次的特质,大部分社会研究都将定序变量作为定类变量看待,也就是采用 Lambda 或者 tau-y 系数测量定类与定序的关系。
定序与定距
大部分社会研究都将定序变量作为定类变量看待,也就是采用相关比率测量定序与定距的关系。
双变量相关性的推论统计
在样本中发现的相关性,不能直接推论到总体中去,需要进行推论统计分析。
推论统计都是以抽样分布为基础,来检验虚无假设,进而知道研究假设的正确可能性。
常用的方法有卡方检验、Gamma 检验、\(F\) 检验、积矩相关 \(r\) 与回归系数 \(b\) 的检验。
\(\chi^2\) 检验
如果两个变量都为定类变量,可用 \(\chi^2\) 检验来推论在总体中两者是否相关,卡方检验是非参数检验法的一种。
使用前提:① 样本随机、② 两个变量为定类。
之前介绍过,两个定类变量相关程度用 Lambda 和 tau-y 表示。还可以根据 \(\chi^2\) 的值来测量两个定类变量的相关性。
Phi 相关系数、列联相关系数以及克拉默的 V 相关系数是基于卡方值发展出来的相关系数,但这三个系数都没有消除误差比例的意义。
\(\chi^2\) 检验的 SPSS 实现
\(\chi^2\) 检验结果的解读
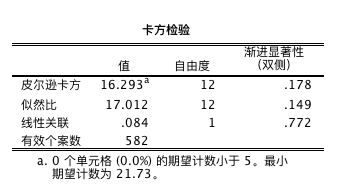
卡方检验表格中的数据显示,双侧渐进显著度大于 0.05,表明应该接受虚无假设,即不同商店的顾客满意度不存在统计显著性差异,处于同一水平。
以 APA 格式撰写 \(\chi^2\) 检验结果
对 XXX 公众所做的调查发现,受教育程度与年收入有关,受教育程度越高,年收入也越高,\(\chi^2\)(9,\(N\)=690)=123.035, \(p\)<0.01, Cramer 的\(V\)=0.244。进一步分析发现:初中以下学历者年收入大多在 12999 元以下;高中学历年收入大多在 13000~29999 元之间;大学学历者年收入多在 60000 元以上;研究生学历者半数以上年收入在 60000 美元以上。
Gamma 检验
如果两个变量都为定序变量,使用 \(Z\) 检验或 \(t\) 检验来推论总体中的 Gamma 是否等于 0。
使用前提:① 样本随机,② 两个变量为定序,③ 样本较大(最好大于 100)。
定序变量相关性检验的 SPSS 实现
定序相关性检验结果的解读
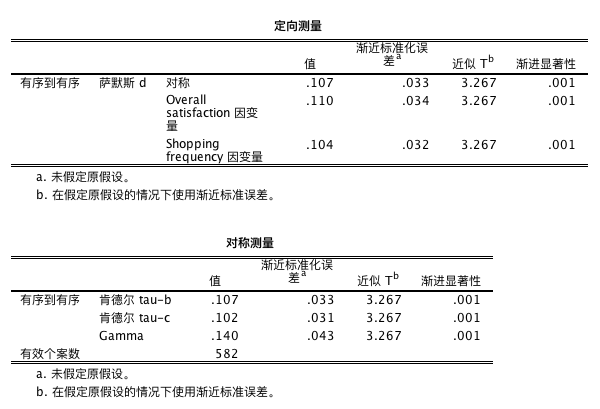
检验结果表明,不同系数的渐进显著性都小于 0.05,我们可以得出结论,购买频率和总体满意度之间存在统计显著性关系。然而,各相关系数都小于 0.15,表明这两个变量之间的相关性非常弱。
以 APA 格式撰写 Gamma 检验分析结果
学生课前预习情况的好坏与课堂表现的好坏存在显著的正相关关系,课前预习情况越好课堂表现越好,γ(22)=0.940,p<0.05。
在 Goodman & Kruskal’s Gamma 检验分析中相关系数就是最常用的效应量,相关系数为±0.1、±0.3、±0.5,分别对应小、中和大的效应量。
平均数差异检验—— \(t\) 检验
独立样本 \(t\) 检验适用于两个群体平均数的差异检验,其自变量为二分定类变量,因变量为定距变量。
使用前提:① 样本随机,② 有一个变量是定距变量,③ 自变量只有两个值,④ 两组群体间具有方差同质性。
\(H_1\):不同性别的运动员在社会支持方面存在显著差异。
独立样本 \(t\) 检验的 SPSS 实现
独立样本 \(t\) 检验结果的解读
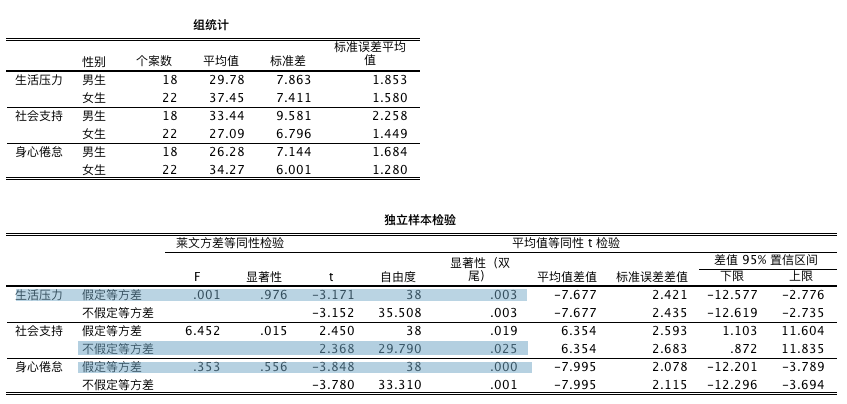
先看莱文方差等同性检验结果,如果该栏检验的显著性 \(p>0.05\),则表明方差同质,看假定方差相等一行的内容,否则看不假定方差相等一行。根据这一规则,我们看到社会支持一行的显著性为 0.025,小于 0.05,因此拒绝虚无假设,接受研究假设,即不同性别的运动员社会支持方面存在统计显著性差异,从表中可以看出,男性运动员获得的社会支持高于女性运动员。
定类与定距变量之间的相关系数
独立样本 \(t\) 检验通过后,还可以计算 Eta 的平方,反映出变量之间的关系强度。具体操作参见 eta 平方系数的 SPSS 实现过程。
计算效应量
独立样本 \(t\) 检验对应的效应量可用 Cohen 的 \(d\) 值,公式为:
\[ d = t\sqrt{\frac{n_1+n_2}{n_1n_2}} \]
以 APA 格式撰写独立样本 \(t\) 检验结果
研究者以 XX 为受试者,其中接受信息科技融入英语教学者的英语能力(\(M\)=83.47,\(SD\)=4.80,\(N\)=19)并未显著不同与接受一般英语教学的学生(\(M\)=78.82,\(SD\)=8.39,\(N\)=17),两组的平均得分差异为 4.65,95%置信区间为 [-0.12,9.42],\(t\)(25)=2.01,\(p\)=0.055,效应量\(d\)=0.68。
SPSS 中没有此效应量计算,可在线计算:http://www.99cankao.com/statistics/effect-of-size-calculator.php
单因素方差分析与 F 检验
分析一个定类变量和一个定距变量之间的关系,可以用相关比率。其推论检验常用单因方差分析(one-way analysis of variance)中的 \(F\) 检验,其目的是推算各组总体中的均值是否相等。
使用前提:① 样本随机,② 有一个变量是定距变量,③ 各组总体都是正态分布,④ 具有相等的方差。
方差分析的原理是将全部方差分解为两部分:消解方差和剩余方差,然后从相互比较中推论变量在总体中是否相关。
\(F\) 比率就是消解方差与剩余方差的对比,如果 \(F\) 值越大,两个变量相关的可能性也越大。
单因素方差分析的 SPSS 实现
单因素方差分析结果解读流程

ANOVA 表格解读
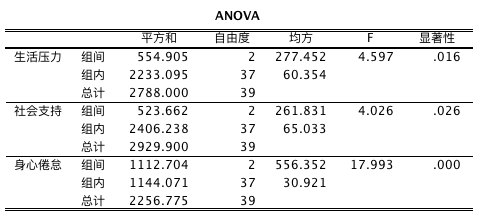
从计算结果可以看出,\(F\) 检验的显著性都小于 0.05,可以说,不同年龄的运动员在生活压力、社会支持、身心倦怠方面存在显著性差异。
但具体是在哪几对配对组上存在显著性差异,还需要根据事后比较方能得知,必须从多重比较摘要表中进行判断。
而多重比较摘要表的数据阅读,又要依据方差同质性检验结果。因此,应该再看方差同质性检验结果。
方差同质性检验结果
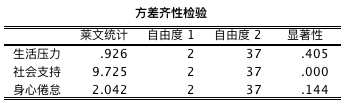
根据表格中的显著度,可以认为,该群体样本中的社会支持变量方差不具有同质性。
在实际操作中,当方差违反同质性假定时,我们选择 SPSS 提供的四种异质事后比较方法:塔姆黑尼 T2、邓尼特 T3、盖姆斯-豪厄尔、邓尼特 C。
如果方差同质,则选择假定等方差中的 LSD、scheffe、Tukey HSD 等事后比较方法。
多重比较结果
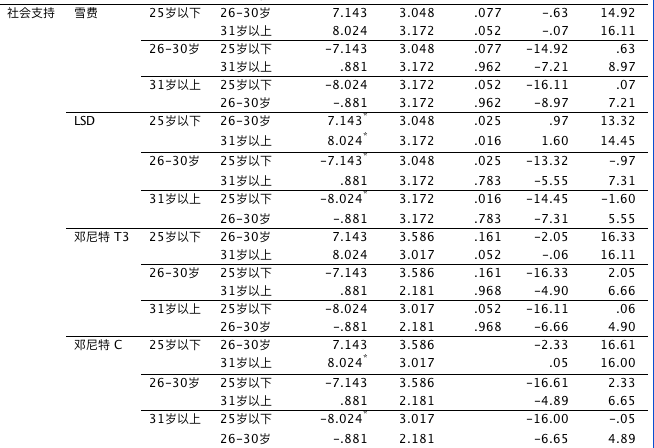
tips:查看平均差异列中的数值为整数且加注星号的组合即可,负数者可不理会。
社会支持变量的方差不同质,因此在看多重比较结果时,应该看塔姆黑尼 T2、邓尼特 T3、盖姆斯-豪厄尔、邓尼特 C 等行的结果。而不看方差同质的事后比较结果。从表中数据可以看出,社会支持变量在邓尼特 T3 法事后检验中没有体现出显著性差异,而在采用邓尼特 C 事后检验法中,“25 岁以下”年龄组的社会支持显著高于“31 岁以上”年龄组。
事后比较方法
常用的事后比较方法有:
- HSD(honestly significant difference) 最实在显著差异法
- N-K(Newman-Keul’s method)纽曼氏法
- S(Scheffe’s method) 薛氏法
S 法较 HSD 和 N-K 法严格,进行组别间的事后比较时,不容易达到显著水平。
以 APA 格式撰写单因素方差分析结果
手部稳定性会因睡眠剥夺时间而有差异,\(F\)(3,28)=7.50,\(p\)=0.001,效应量\(\eta^2=0.4455\)。使用 Tukey 法进行事后检验,30 小时未睡者(\(M\)=6.25,\(SD\)=2.12)显著比 12 小时未睡者(\(M\)=3.00,\(SD\)=1.51)及 18 小时未睡者(\(M\)=3.50,\(SD\)=0.93)更不稳定,其他组之间没有显著差异。
积矩相关与回归系数的检验
积矩相关系数及回归系数的检验,在 SPSS 计算系数的结果中,就已经实现了。具体操作见简单线性回归分析的 SPSS 实现过程。
以 APA 格式撰写简单回归分析结果
研究者进行简单回归分析,以阅读素养为效标变量,阅读态度为预测变量,\(\beta\)=0.48,\(t\)=2.89,\(p\)=0.007,因此阅读态度是阅读素养显著的预测变量,并能解释 23% 的变异量。
双变量相关性及其检验方法总结
| 两变量的测量层次 | 相关测量法 | 假设检验 |
|---|---|---|
| 定类-定类 | λ,tau-y | χ2 |
| 定类-定序 | ||
| 定序-定序 | G,Dy | Z 检验或 t 检验 |
| 定类-定距 | Eta Eta2 | F 检验或 t 检验 |
| 定序-定距 | ||
| 定距-定距 | r、r2、b |
多变量统计分析
多变量统计分析的分类
社会现象是复杂的,两个变量之间的关系往往受其他变量的影响。除了进行单变量和双变量的统计分析之外,还要进行多变量的分析。
多变量分析可依据研究目的分为三大类:① 详析分析,② 多因分析,③ 多项相互关系分析。
详析分析
详析分析所关心的是两个变量的关系,从而引进其他变量,加深了解这两个变量的相互关系。
最简单的详析分析,就是使用多重列联表分析,进行多个变量之间关系的分析。
多因分析
多因分析的目的是要了解多个自变量对某个因变量的共同影响和相对效应。
多项相互关系分析
多项相互关系分析的目的是简化众多变量之间的相互关系。如:
因素分析。
多元回归分析
回归
回归是英国统计学家弗朗西斯·高尔顿在研究父代身高与子代身高之间的关系时提出来的。
回归分析既可以用于探索和检验自变量与因变量之间的因果关系,也可以给予自变量的取值来预测因变量的取值,还可以用于描述自变量与因变量之间的关系。回归分析是量化研究中最重要的方法。
回归的特点就在于它把观测值分解成两部分——结构部分和随机部分。结构部分表示因变量与自变量之间的结构关系,表现为“预测值”,随机项部分表示观测项中未被结构项解释的剩余部分(被忽略的结构因素、测量误差和随机干扰)。
回归分析的相关概念
净相关与部分相关:
所谓净相关(或称为偏相关 partial correlation),是指在计算两个连续变量的相关时,将第三个变量与两个相关变量的相关予以排除之后的纯净相关。部分相关(part correlation)是指净处理第三个变量与两个变量中的某一个变量的相关所计算出来的相关系数。
残差:残差是指将 X 值带入回归方程所得到的数值与观察值之间的差值。表示利用回归方程无法准确预测的误差。
简单回归方程
通常采用最小二乘法(ordinary least squares)计算回归系数。
了解简单回归的原理是学习多元回归的基础。
多元线性回归分析
多元线性回归分析是多因分析的一种。回归分析中的自变量也称为预测变量或解释变量,而因变量又称为效标变量或反应变量。多元线性回归分析的目的在于找出一个自变量的回归方程式,以便说明一组预测变量与效标变量之间的关系。
研究问题案例:
H1:第三人效果强度与性别、学历、专业、节目收看量、认知卷入度、外部行为卷入度、心理相对理性度、短信投票、粉丝身份、节目质量评价之间的关系。
“心理相对理性度”对于“第三者效果强度”的影响最为显著。
多元回归的优势在于它能够提供在控制其它因素以后某一自变量对因变量的偏效应或净效应。
多元线性回归分析对自变量的要求
自变量应该为定距变量。
若自变量为定类变量最好不要纳入到回归分析中,除非此定类变量与效标变量关系甚为密切。
如果要将定类变量纳入预测变量,则先要将定类变量转化为虚拟变量(dummy variable)。
虚拟变量
如果自变量不是定距变量,在纳入回归分析模型前,应先转化为虚拟变量。
例如:家庭类型,1 代表完整家庭,2 代表单亲家庭,3 代表他人照顾家庭,4 代表隔代教养家庭。转化为如下 3 个虚拟变量:
| id | 家庭类型 | fam1 | fam2 | fam3 |
|---|---|---|---|---|
| 1 | 1 | 1 | 0 | 0 |
| 2 | 2 | 0 | 1 | 0 |
| 3 | 3 | 0 | 0 | 1 |
| 4 | 4 | 0 | 0 | 0 |
上述参照组为水平 4(隔代教养家庭),虚拟变量 fam1 为“完整家庭组与隔代教养家庭组”的对比,其它两个类似。
SPSS 多元线性回归分析的不同方法
SPSS 提供 5 种选取变量的方法:强迫进入法(enter)、逐步(stepwise)、向前(forward)、向后(backward)、删除法(remove)。
强迫进入法将所有预测变量同时纳入模型中,用于解释所有自变量对因变量的整体预测力。
逐步多元回归,挑选只对因变量有显著预测力的自变量,其余未达到显著水平的自变量会被排除在回归模型之外。
多元线性回归分析的使用前提
- 正态性,效标变量在预测变量的各个水平上需为正态分布。
- 效标变量的各个观察值必须是独立的。
- 各预测变量之间没有多元共线性关系,即自变量之间没有高度相关(相关系数>0.70)。
- 预测变量与效标变量之间呈线性关系。
- 残差独立性假定。不同预测变量产生的残差之间的相关性为 0。
- 残差等分散性。
共线性诊断
共线性问题是影响多元回归分析的最重要因素之一。
统计软件一般提供容忍度(tolerance)或方差膨胀因素(variance inflation factor,VIF)来评估共线性的影响。
除了个别解释变量的共线性检验之外,整体回归模型的共线性诊断也可以通过特征值(eigenvalue)与条件指数(conditional index,CI)来判断。
CI 值低于 30,表示共线性问题缓和,30-100 之间,表示回归模型具有中至高度共线性,100 以上,则表示严重的共线性。
强迫进入变量法的 SPSS 实现
强迫进入变量法输出结果的解读-相关性
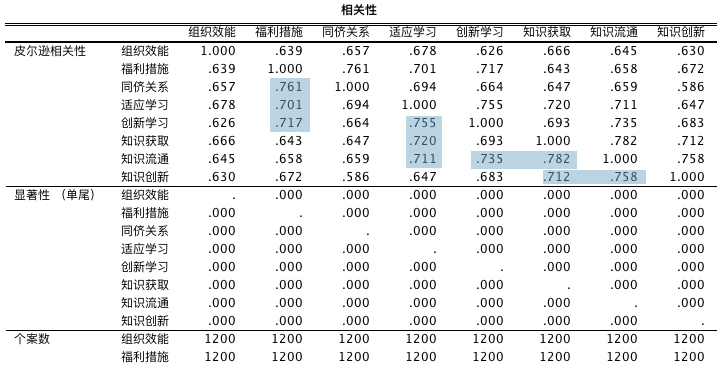
相关性结果显示,7 个自变量与因变量之间存在显著性相关关系;但有自变量之间的相关系数大于 0.7,可能存在共线性问题。
如果两个自变量存在共线性问题,则可以选取一个比较重要的进入回归模型。
回归分析的假设检验
回归分析的假设检验包括两方面的内容:
- 模型整体检验,即检验根据样本数据建立的回归方程在总体中是否也有解释力;
- 回归系数检验,即检验该方程中自变量对因变量的影响在总体中是否存在。
强迫进入变量法输出结果的解读-模型解释力

\(R^2\)的值为 0.58,表明回归模型中的所有自变量,可以解释因变量的 58% 的变异量。
强迫进入变量法输出结果的解读——模型整体检验
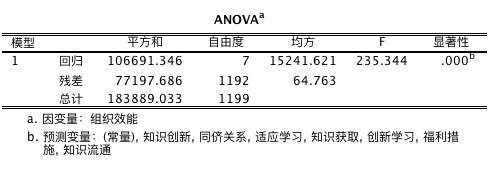
方差分析的显著性检验 p 小于 0.05, 表明回归模型整体解释达到显著水平,至于是哪些回归系数达到显著,还需要看其他表。
强迫进入变量法输出结果的解读-回归系数检验
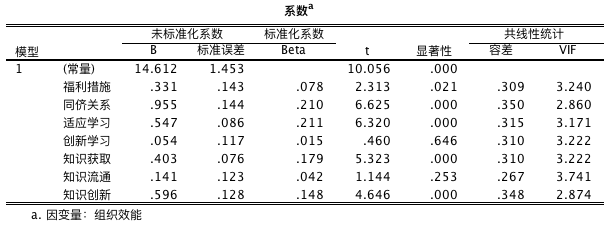
标准化回归模型为:组织效能 = 0.08 福利措施 + 0.21 同侪关系 + 0.21 适应学习 + 0.02 创新学习 + 0.18 知识获取 + 0.04 知识流通 + 0.15 知识创新
系数意义解读:对于福利措施变量,福利措施每增加一个单位,组织效能平均增加 0.08 单位。
自变量是否有多元共线性问题,可用三个数据判别:容忍度小于 0.1、方差膨胀因素大于 10、条件指标大于 30。
表中的容忍度、方差膨胀因素表明,自变量多元共线性问题不是很明显。
强迫进入变量法输出结果的解读-CI
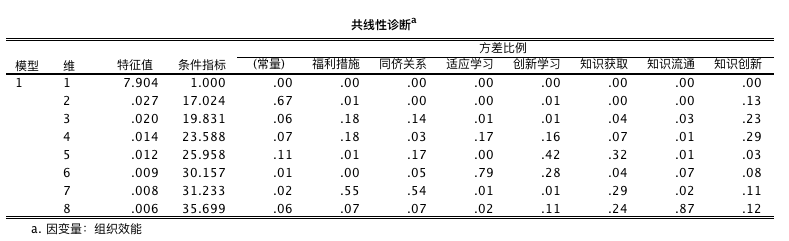
自变量是否有多元共线性问题,可用三个数据判别:容忍度小于 0.1、方差膨胀因素大于 10、条件指标大于 30。
表中条件指标中有三个变量大于 30,表明自变量有轻微共线性问题。
强迫进入变量法输出结果的解读–正态
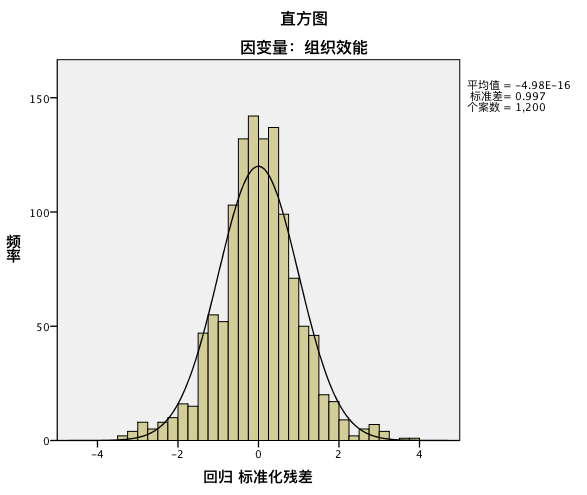
图中形状表明,样本观察值大致符合正态性的假定。
强迫进入变量法输出结果的解读-整体
总体而言,分析结果表明,多元回归分析的前提条件基本满足,回归分析模型具有显著性,7 个自变量整体能解释 58%的变异量,模型具有一定的解释力,其中同侪关系、适应学习对组织效能有较高的解释力,未达到显著性的自变量(创新学习、知识流通)对组织效能的变异解释较小。
多元回归分析结果撰写案例
以性别、读书困难、父亲受教育念书对阅读素养进行多元回归分析,整体效果是显著的,\(F\)(3,16)=9.81,\(p\)<0.001,\(R^2\)=0.45。个别变量分析,读书困难 [\(\beta\)=-0.329,\(t\)(36)=-2.35,\(p\)=0.024] 及父亲受教育程度 [\(\beta\)=0.431,\(t\)(36)=3.23,\(p\)=0.003] 可显著预测阅读素养。性别则无法显著预测阅读素养,\(b\)=18.69,\(t\)(36)=0.75,\(p\)=0.459。
逐步多元回归分析
逐步多元回归分析是一种探索性的多元线性回归方法,此方法同时使用前进选取和后退删除方法,计算出最佳的多元回归分析模型。
逐步多元回归分析的操作及结果解释和强制进入分析法类似。
量表项目分析
项目分析基本理念
项目分析的主要目的在于检验编制的量表或测验个别题项的适合或可靠程度,项目分析的检验就是探究高低分受试者在每个题项的差异或进行题项间同质性检验,项目分析的结果可作为个别题项筛选或修改的依据。
测试分析指标
\[ 难度公式:P=(P_H+P_L)\div 2 \] \[ 鉴别度指数: D = P_H-P_L \]
在试题分析时,将测验总得分前 25%-33% 设为高分组,测验总得分后 25%-33% 设为低分组。其中 \(P\) 为试题的难度,\(P_H\) 代表高分组在某个题项答对人数的百分比,\(P_L\) 代表低分组在某个题项答对人数的百分比。
鉴别度表示的是高分答对组答对的比例与低分组答对百分比的差异值。
\(P\) 值越大,题目越容易,建议在 [0.2,0.8] 之间。\(D\) 值在 [-1,1] 之间,为负值时,表示不具鉴别度,为正值时,越大鉴别度越高,建议在 0.3 以上。
量表临界比值法
量表项目分析的判别指标中,最常用的临界比值法(critical ration),又称为极端值法。主要目的在于求出题项的决断值(或叫临界比)。决断值根据高分组与低分组在每个题项的平均数差异的显著性而定,其原理与独立样本 \(t\) 检验相同。
可使用独立样本 \(t\) 检验求得的 \(t\) 值作为决断值或临界比值,\(t\) 值越高,表示题项的鉴别度越高。
项目分析的主要操作步骤
- 确定题项的方向与分值。
- 计算所有受试者的总分。
- 通过总分排序,求出高低分组的临界点。
- 找出高低分组上下 25%-33% 处的分数。
- 按照临界值将量表得分进行分组。
- 检验高低组在每个题项的差异。
- 将未达到显著性的题项删除。
27% 分组法适用于测试,在量表检验中,采用 25%-33% 的分组法均可,样本少,就用低比例。
如果题目数量充足,还可删除鉴别力比较低(\(t\) 值小于 3)的题项。
根据相关系数筛选题项
还可以采用同质性检验作为筛选的指标,如题项与总分的相关越高,表示题项与整体量表的同质性越高,所要测量的心理特质或潜在行为更为接近。
相关系数小于 0.4,或者相关系数未达到显著的题项,最好删除。
同质性检测——信度检测
信度(reliability)代表量表的一致性或稳定性,信度系数也可以作为同质性检验指标之一。
在社会科学领域,采用最多的是克隆巴赫 α 系数(Cronbach α),该系数又称为内部一致性 α 系数。
如果题项删除后量表整体信度系数比原先的信度系数(内部一致性 α 系数)高出许多,则此题项与其他题项所要测量的属性或心理特质可能不相同,代表同质性不高,在项目分析时可考虑删除。
克隆巴赫 α 系数在 SPSS 中的实现
选择分析菜单中的刻度,再选择可靠性分析,统计量中选择删除项后的标度。
克隆巴赫 α 系数输出结果分析
一份理想的量表,其总量表的内部一致性 α 系数至少要在 0.800 以上。
修正的项目总相关系数,是每一个题项与其他题项加总后(不包含原题项)的相关系数,该系数小于
0.400,表示该题项与其余题项所要测量的心理或潜在同质性不高,可删除。
删除项后的克隆巴赫 Alpha,表示的是该题删除后,整个量表的
α 系数。若删除该题后, α
值变大,表示该题项与其余题项不同质,可删除。
在采用内部一致性 α 系数作为判断指标时,必须注意不同维度的题项应分别处理。若是量表或测量所包含的因素构念是两种以上不同的面向,这些面向的加总分数并没有实质的意义(例如:校长领导量表中的“权威取向”和“关怀取向”)。此时内部一致性 α 系数要以各自不同的因素构念为子量表分别计算,而不能估计整个量表的信息系数。
同质性检测——共同性与因素负荷量
共同性表示题项能解释共同特质或属性的变异量。因素负荷量(factor loading)则表示题项与概念因素关系的程度。
在 SPSS 中计算量表题项的共同性与因素负荷量
执行分析菜单中降维模块,选自因子,再选择提取,将要提取的因子数,设置为
1,点击确定即可。
量表题项的共同性与因素负荷量结果解读
共同性萃取值(Extraction),是个别题项与共同因素间多元相关系数的平方,相当于回归分析中的 \(R^2\)。共同值若低于 0.20,表示个别题项与共同因素之间的关系不密切,可考虑删除。
解释总变异表中(Total Variance
Explained),可看出只抽取的一个共同因素的特征值和可以解释量表变量的比例(Extraction
Sums of Squared Loadings)。
成分矩阵表(Component
Matrix)中的第二列为因素负荷量,相当于回归分析中的回归权数。若题项的因素负荷量小于
0.45,可考虑删除题项。
项目分析时的一般判断指标总结
- 极端组比较法,使用决断值,一般要求决断值大于等于 3。
- 题项与总分的相关法,一般要求题项的总分的相关值,大于等于 0.4。
- 使用同质性检验的方法,一般要求题项删除后的 α 小于等于量表信度值;共同性大于等于 0.2,因素负荷量大于等于 0.45.
量表因素分析
效度的基本概念
所谓效度,是指能够测到该测验所欲测心理或行为特质到何种程度。研究的效度包括内在效度和外在效度。
内在效度是指研究叙述的正确性与真实性;外在效度则研究推论的正确性。
- 效度是指测验结果的正确性或可靠性,而非测验工具本身。
- 效度并非全有或全无,只是程度上有高低不同的差别。
- 一份高效度的测验工具,适用于特定的群体,施测于不同的受试者,可能会导致测验结果的不正确。
- 效度无法实际测量,只能从现有信息中做逻辑推论或做统计检验。
APA 从不同维度,将效度分为三类:
- 内容效度(content validity) 也叫作逻辑效度,指量表内容的适切度。
- 效标关联效度(criterion-related validity) 指测验与外在效标间关系的程度。
- 建构效度(construct validity)指能够测量出理论的特质或概念的程度,指实际的测验分数能解释多少某一心理(概念)特质。
此外,有学者建议还可采用专家效度。专家效度,指根据专家学者的意见,统计分析题项。
建构效度检验
由于建构效度有理论的逻辑分析为基础,同时又根据实际所得的数据来检验理论的正确性,因此是一种最严谨的效度检验方法,并且可以避免内容效度有逻辑分析,但无实证依据的问题。
建构效度检验的步骤:
- 建立假设性理论建构
- 编制量表
- 试调查
- 用统计方法对试调查数据进行分析
统计学上,检验建构效度的最常用方法就是因素分析。
因素分析的基本原理
因素分析可以抽取变量间的共同因素,以较少的构念代表原来较复杂的数据结构。它根据变量间彼此的相关,找出变量间潜在的关系结构,变量间简单的结构关系称为成分(components)或因素(factors)。
因素分析的目的,即在因素结构的简单化,希望以最少的共同因素对总变异量作最大的解释,因而抽取的因素越少越好,但抽取因素的累积解释的变异量则越大越好。
因素分析的步骤
- 计算变量间相关矩阵或共变量矩阵
- 估计因素负荷量
- 决定转轴方法
- 决定因素并命名
计算变量间相关矩阵或共变量矩阵
如果一个变量与其他变量相关很低,在因素分析中,结合变量的共同性与因素负荷量,可考虑剔除此变量。
估计因素负荷量
决定因素负荷量的方法,有:
- 主成分分析法(principle components analysis)
- 主轴因素法(principle axis factoring)
- 一般化最小平方法
- 未加权最小平方法
- 极大似然法
- Alpha 因素抽取法
- 映象因素抽取法
最常用的为主成分分析法与主轴因素法。
主成分分析法
主成分分析法是以线性方程式将所有变量加以合并,计算所有变量共同解释的变异量,该线性组合称为主要成分。
第一次线性组合所解释的变异量最大,分离此变异量后剩余的变异量经第二个方程式的线性组合,可以抽离出第二个主成分。
以此类推,每一成分的解释变异量依次递减。
主成分分析适用于单纯简化变量成分,以及作为因素分析的先前预备历程。
主轴因素法
主轴因素法是一种利用反复计算以估计共同性及其解值的方法,此一方法前半段的估计与主成分法类似,然后再以指标间的相关系数矩阵并应用主成分估计法获取结果,之后,经综合判断所需萃取的共同因素个数,再根据相关数据估计各变量的共同性。
主轴因素法与主成分分析法不同的是,主轴因素法并没有就此结束,而是要再利用估计所得的结果进行下一回合估计,并不断反复估计,直到共同性收敛到一个数值为止。
决定转轴方法
常用的转轴方法,有:
- 最大变异法
- 四次方最大值法
- 相等最大值法
- 直接斜角转轴法
- 最优转轴法
其中,前三者属于直交转轴法(因素与因素间没有相关),后两者属于斜交转轴法(因素与因素之间彼此有某种程度的相关)。
转轴的主要目的是协助因素更具心理解释意义,亦即达成简单结构的原则。
转轴方法的选择
有学者(Nunnally、Bernstein)认为,当因素间的相关系数在 0.3 以上时,最好采用斜交转轴法,反之采用直交转轴法。也有学者建议在因素分析时,同时采用斜交转轴法和直交转轴法,并进行两者之间的比较。若因素数量和因素包含的变量内容差不多,则直接采用直交转轴法的结果,否则,采用斜交转轴法结果去解释。
因素分析的筛选原则
- Kaiser 的特征值大于 1 的方法
- 陡坡图检验法(scree plot test)
- 方差百分比决定法
- 事先决定准则法
因素分析在 SPSS 中的实现
- 选择
分析菜单中的降维中的因子分析, - 在
描述选项卡中,选择系数、显著性水平、再生、决定因子、反映像以及KMO 检验。 - 在
提取选项卡中,选择合适的方法,在输出中,选择碎石图。 - 在
旋转选项卡中,选择最大方差法或直接斜交法,选择负荷图。 - 在
得分选项卡中,选择保存为变量。 - 在
选项选项卡中,选择按大小排序。 - 点击
确认,进行因素分析。
界面中的变量是用在方程中的,
选择变量是过滤个案的。 比如说个案要求某变量中的值 >6,
则那个变量 >6 的个案才进入方程。
因素分析结果的解读
相关性矩阵 Correlation Matrix
该表为变量的相关性系数矩阵即显著水平,最下方的数据为相关矩阵的行列式值,数值为 0,则无法进行因素分析。
若一个变量与其他多数变量的相关系数均未达到显著,或相关系数均很低,则表示此变量与其他变量所欲测出的概念特征的同质性不高,可以考虑将此变量删除。
KMO 和巴特利特检验
KMO 值介于 0 和 1 之间,该值越大,表示变量间的共同因素越多,变量间的净相关系数越低,越适合进行因素分析。KMO 小于 0.5,则不适合进行因素分析。
球形检验(Bartlett’s Test of Sphericity)的结果,若通过检验,则代表总体的相关矩阵间有共同因素存在,适合进行因素分析。
反映像矩阵 Anti-image Matrices
若以第 n 个题项为因变量,其余各题项为自变量进行多元回归分析,此第 n 个因变量能被自变量预测的部分称为\(P_n\),不能被预测的部分称为\(E_n\),\(P_n\)为该变量的映像,\(E_n\)即为该变量的反映像。根据每个变量的反映像\(E_n\),即可求出各变量的反映像矩阵。
反映像相关系数越小,表示变量间共同因素越多,变量越适合进行因素分析。
反映像相关矩阵的对角线数值代表每一个变量的取样适当性量数(Measure of Sampling Adequacy), MSA 类似于 KMO,越接近 1,表示越适合进行因素分析,一般而言,如果 MSA 值小于 0.5,表示该题项不适合进行因素分析。
公因子方差
与项目分析时的筛选标准一致,若共同性低于 0.2,可考虑删除题项。
总方差解释
选择特征值大于 1 以上的,作为保留成分的标准。在决定成分题项的时候,还需要考虑碎石图、题项的数量(大于 3)、是否包含共同因素、是否存在实质性意义等等因素对因素进行命名。
合理的因素:题项最少三个;题项具有类似的潜在特质,且可以命名。
若萃取后保留的因素联合解释变异量能达到 60% 以上,表明萃取后保留的因素相当理想。如果萃取后的因素能联合解释所有变量 50% 以上的变异量,则萃取的因素也可以接受。
碎石图
碎石图可以帮助使用者决定因素的数目,判断标准是取坡线突然剧升的因素,删除坡线平坦的因素。
成分矩阵
矩阵中的数值为各题项在因素中的负荷量,该值越大,表示该题项变量与这个因素间的关联越大。
该表应和旋转后的成分矩阵一起解读。
因素分析的建议
- 应先进行探索性的分析,然后删除不适合因素分析的题项后,再进行正式的因素分析。
- 对社会科学的量表进行因素分析时,建议采用正交和斜交互相验证的方式。
- 因素的命名要有理论依据,或在理论依据的基础上进行发展。
写作规范
格式为什么重要
为了保障学术文章的清晰和一致,出版者应遵守一系列规则,以发表为目的的论文作者必须按照出版界已经确立的规则撰写文章,混乱的格式会分散读者的注意。
标点符号
- 标点符号后的空格 在以下英文标点符号之后要空一格:
- 逗号、冒号、分号;
- 分割参考文献中各条文献不同信息单元中的句号;例如:
Myers, D. G., & Twenge, J. M. (2016). Social psychology (12e [edition]). McGraw-Hill. - 人名首字母缩写后的句号。例如:
J. R. Zhang
- 方括号
- 围住置信区间的值。例如:
[-7.2, 4.3] - 围住直接引语中那些非引语作者的文字。
- 围住置信区间的值。例如:
数目
- 用阿拉伯数字表述的数目
- 数目在 10 及以上。
12 岁以上的学生 - 出现在摘要和正文图示中的数目。
- 后面紧接测量单位的数目。
10.54 cm - 代表统计或数学功能的数目、分数或小数、百分比、比率、百分位数以及四分位数。
- 序列中的序号、表格编号、书的部分号。
- 数目在 10 及以上。
- 小数的使用
- 当统计量可能大于 1
时,在小数点前面要使用零。例如:
0.23 cm,Cohen's d=0.79 - 当统计量不可能大于 1 时(相关系数、比例、统计显著性水平),不要在小数点前用零。例如:\(p\) = .028
- 报告相关系数、比例以及推断统计量时,保留两位小数点。
- 报告 \(p\) 值时,请报告精确值(例如:\(p\) = .031),精确到小数点后两到三位小数点即可。不过,\(p\) 值小于 .001 要以 \(p\) < .001 的方式报告。
- 当统计量可能大于 1
时,在小数点前面要使用零。例如:
统计内容和数学内容
- 选择有效的呈现方式
- 如果需要呈现三个或更少的数字,首先争取一句话表达。
- 如果需要呈现四到 20 个数字,首先考虑用一个设计良好的表格表达。
- 如果需要呈现 20 个以上的数字,用图表示往往比表格表达更为有用。
- 以下情况需要提供有关统计方法的参考文献:
- 使用不常用的统计方法时,一定要提供参考文献。
- 统计方法的使用方式是非常规的,存在争议的。
- 统计方法本身就是文章讨论的焦点。
- 常用统计方法不用给出公式。新方法或者罕见方法,就一定要给出公式。
- 文本中统计内容的表述要有足够的信息,以允许读者完全理解所做的统计分析。如果描述统计结果已经以图或表的形式呈现,那就没有必要在文本中再用文字重复这些内容。但是可以用文字强调某些具体数据,以更好地解读发现。
统计符号
- 叙述中用到统计术语时,要用术语的名称,不要用术语的符号。例如:
平均值为 XXX,而不是Ms 是。 - 用大写的斜体 \(N\) 表示总样本的数量,用小写的斜体 \(n\) 表示一个部分的数量。
- 几乎所有的统计符号都用斜体,但表示向量和矩阵的符号用粗体,希腊字母用标准体。
常用统计符号和缩写
| 缩写/符号 | 定义 |
|---|---|
| ANCOVA | 协方差分析 |
| ANOVA | 方差分析 |
| \(b\), \(b_i\) | 回归分析中非标准化回归系数的估计值 |
| \(b^*\), \(b_i^*\) | 回归分析中标准回归系数的估计值 |
| CDF | 累积分布函数 |
| CFA | 确认性因素分析 |
| CI | 置信区间 |
| \(d\) | 两样本均值比较样本效应大小的 Cohen 度量 |
| \(df\) | 自由度 |
| EFA | 探索性因素分析 |
| \(f\) | 频数 |
| \(f_e\) | 期望频数 |
| \(f_o\) | 观察频数 |
| 缩写/符号 | 定义 |
|---|---|
| \(F\) | \(F\) 分布,Fisher \(F\) 比值 |
| \(F(v_1,v_2)\) | 第一自由度和第二自由度分别为 \(v_1,v_2\) 的\(F\)值或\(F\)分布 |
| GLM | 一般线性模型 |
| GLS | 一般最小二乘法 |
| \(H_0\) | 虚无假设、零假设,受检验假设 |
| \(H_1\) | 备选假设 |
| LSD | 最小显著性差异 |
| \(M\) 或者 \(\bar{X}\) | 样本均值,算术平均值 |
| MANOVA | 多元方差分析 |
| MANCOVA | 多元协方差分析 |
| \(M_{dn}\) | 中位数 |
| n | 样本数,一般指子样本 |
| N | 总样本数 |
| 缩写/符号 | 定义 |
|---|---|
| OLS | 常最小二乘 |
| \(p\) | 概率 |
| 概率密度函数 | |
| \(r\) | 皮尔逊积距相关系数 |
| \(r_{ab,c}\) | 剔除\(c\)效应后\(a\)与\(b\)之间的净相关 |
| \(r_{a(b,c)}\) | 剔除\(b\)中 c 效应后\(a\)与\(b\)之间的部分相关 |
| \(r^2\) | 确定系数 |
| \(r_s\) | 斯皮尔曼秩次相关系数 |
| \(R\) | 多元相关系数 |
| \(R^2\) | 多元相关系数平方 |
| \(SD\) | 标准差 |
| \(SE\) | 标准误差 |
| SEM | 结构方程建模 |
| \(t\) | \(t\) 分布,\(t\) 检验,\(t\) 检验中的样本 \(t\) 值 |
| 缩写/符号 | 定义 |
|---|---|
| \(V\) | 列联表中 Gramer 度量 |
| \(W\) | 肯德尔和谐系数及其估计 |
| WLS | 加权最小二乘 |
| \(z\) | 标准分;\(z\) 检验的统计量 |
| 希腊字母 | 定义 |
|---|---|
| \(\alpha\) | 统计检验中犯第Ⅰ类错误的概率;克隆巴赫内部一致性指数 |
| \(\beta\) | 统计检验中犯第Ⅱ类错误的概率;回归分析中回归系数的总体参数值 |
| \(\Gamma\) | Goodman-Kruskal 关系指数 |
| \(\Delta\) | 变化增加量 |
| \(\delta\) | Cohen 效应大小的总体值 |
| \(\epsilon^2\) | 方差分析中关系强度的度量 |
| \(\eta^2\) | 关系强度系数 |
| \(\lambda\) | Goodman-Kruskal 相关系数;因素负荷矩阵中的元素 |
| \(\mu\) | 总体均值;期望值 |
| \(\sigma\) | 总体标准差 |
| \(\tau\) | 肯德尔秩次相关系数 |
| \(\Phi\) | 列联表中相关系数 |
| \(\chi^2\) | 卡方分布;卡方检验;卡方检验的样本值 |
图表
设计精良和精美悦目的图表,使得文章沟通更为有效。
图表并不总是有效沟通的最优方式,许多标准统计显著性检验的结果,用文字表述会更加有效。图表过多一方面使得排版困难,另一方面文字被穿插得支离破碎难以阅读。
图表应该设计得可以单独理解。
对图表进行编号
对于所有的图表,都要根据它们在文章中第一次出现的顺序进行编号。编号用纯阿拉伯数字,不要带字母后缀,如表 1,而非表 1a。引用图表时,使用编号(如:正如图 1 所示),而不是参见上图之类的相对引用方式。
复制数据展示许可
如果作者复制或者改编了某个图、表、问卷或者测验项目,需要取得许可,并通过在图表的说明文字中说明图表的原始作者和版权所有者。再现任何图表或者其中的部分,都必须加注,注中说明原始作者和版权所有者。
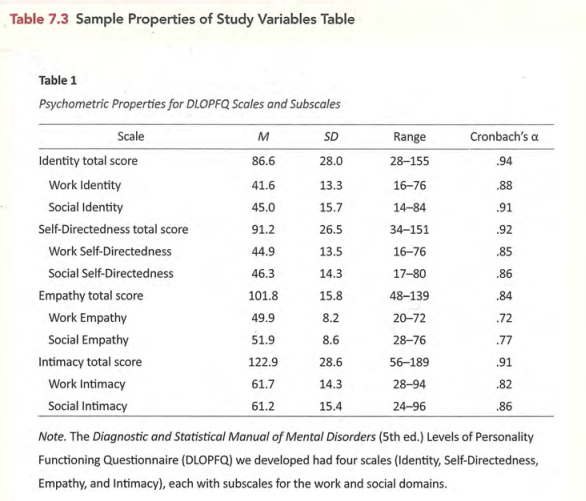
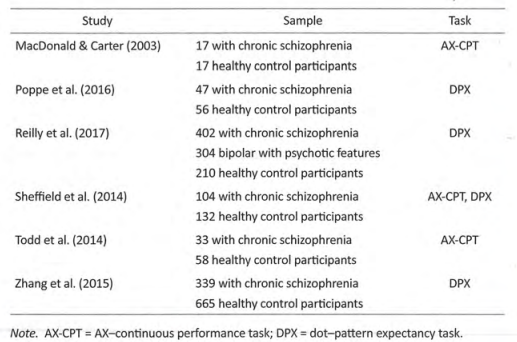
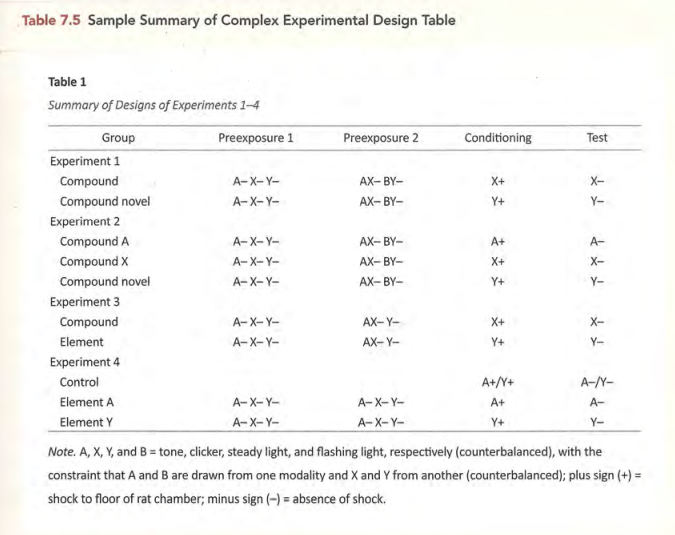
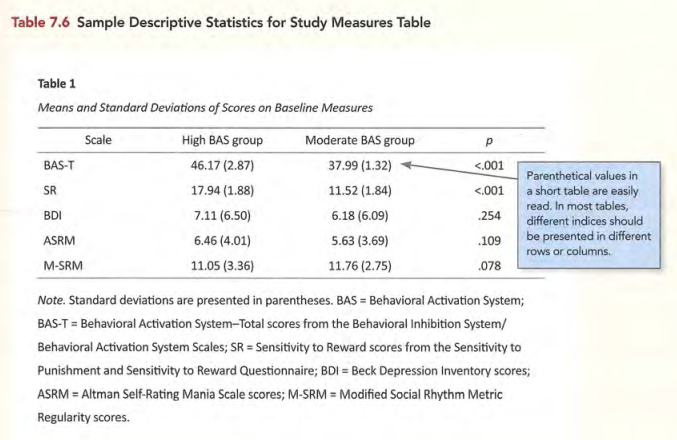
常见表格的标准形式

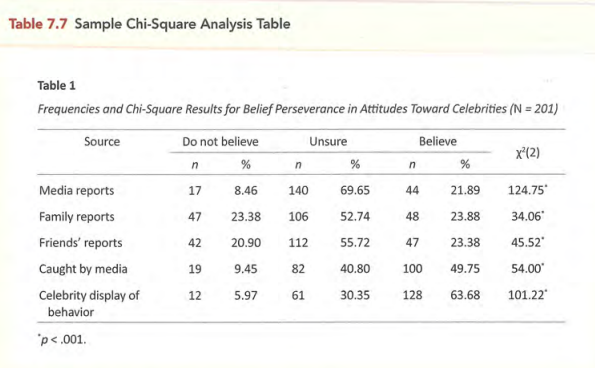
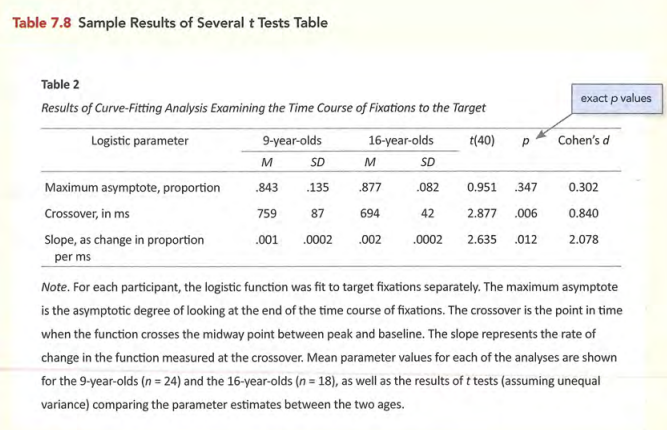
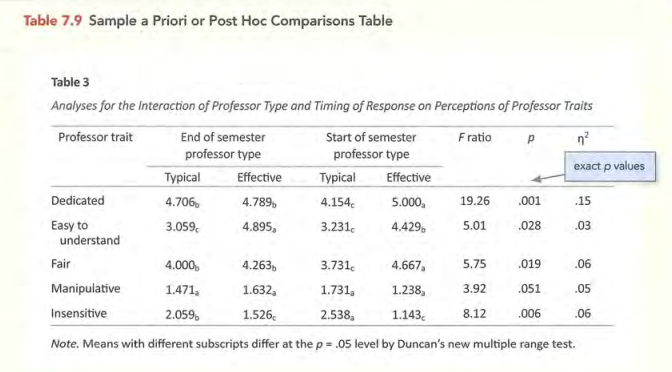
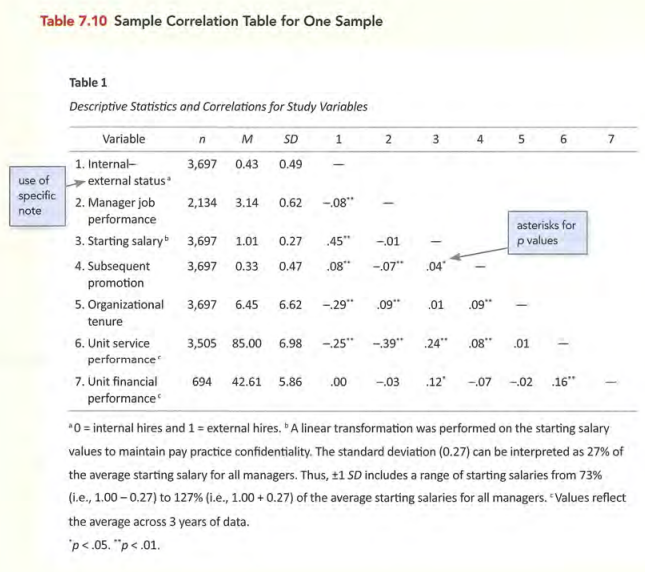

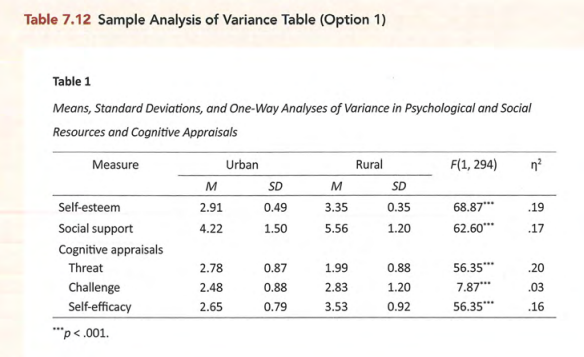
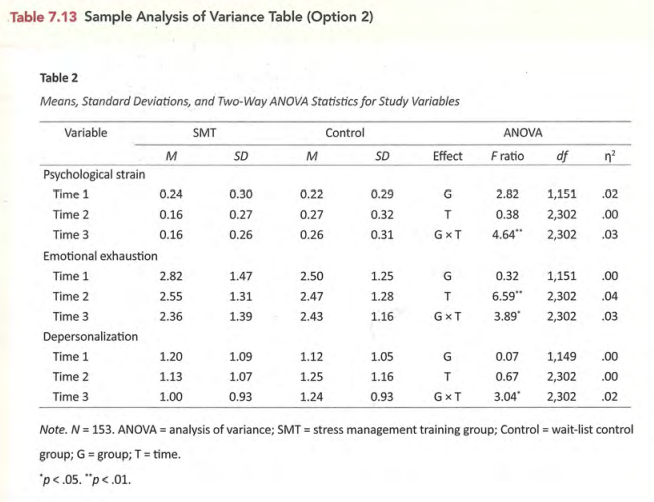

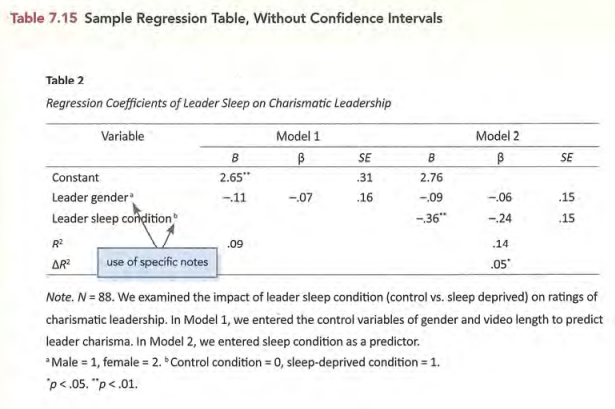
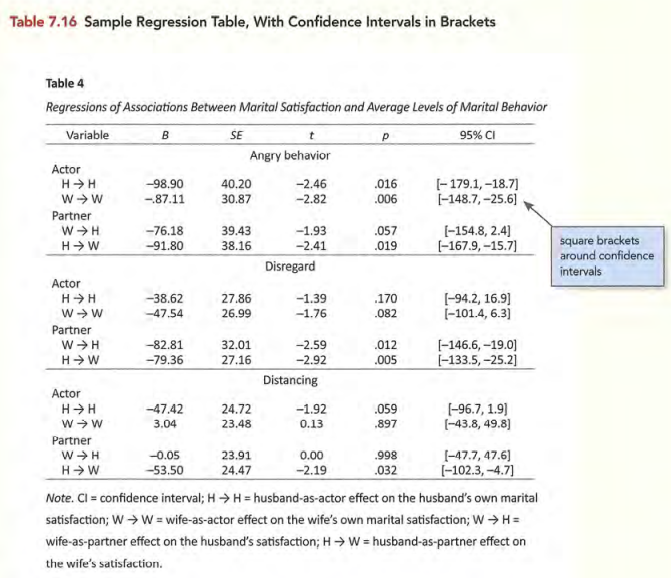
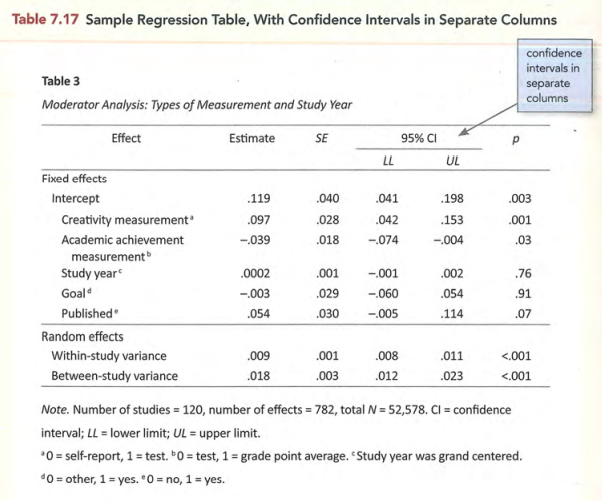


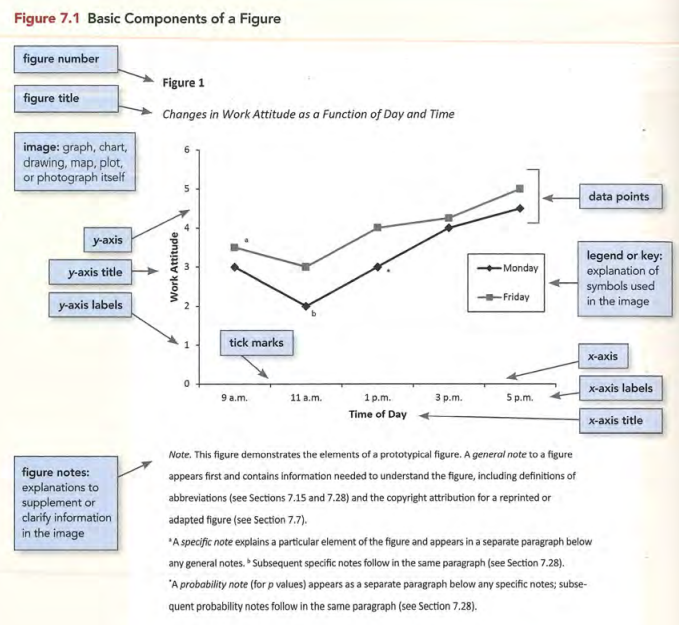
图
一副好图的标准是:简单、清晰、连续以及有信息价值。图要扩大文本的内容,而不是重复其内容;只传递不可或缺的事实;要省略分散视觉的细节;图的各种元素要易于阅读;同类图格式一致;字体简单(例如:Arial, sans serif);数值带有单位;
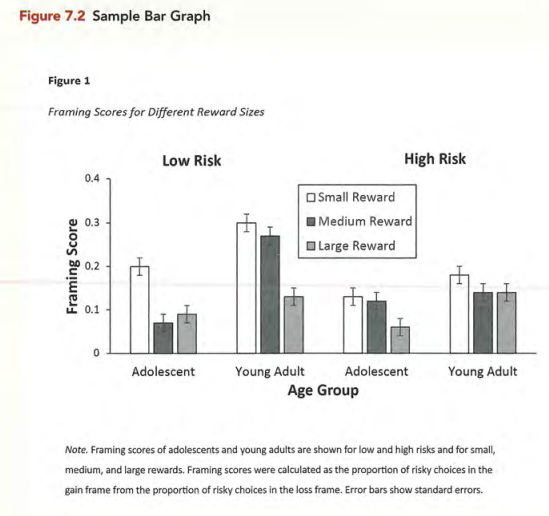
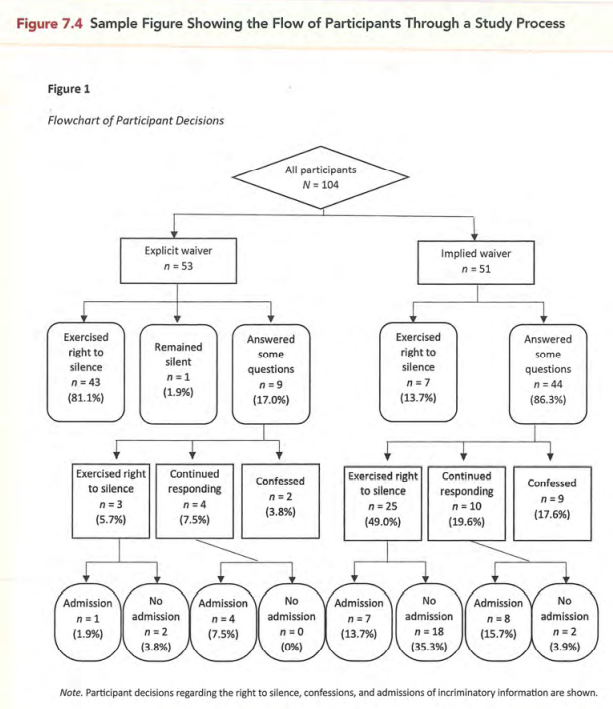
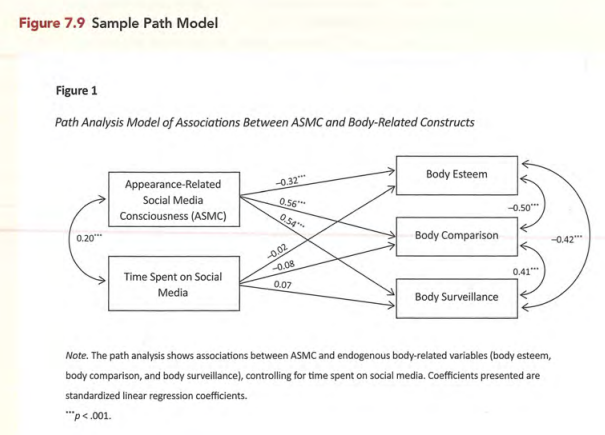
常见问题
使用 SPSS 打开数据文件时出现乱码
出现该问题的原因是编码方式不同,只需要修改合适的编码方式即可。
- 打开一个空的 SPSS,注意是不能有数据的。
- 然后选择
偏好设置》language》Character Encoding for Data and Syntax部分改为Locale's writing system, 下拉菜单中选择Chinese-***,应用设置。
或者修改为 Unicode。
参考文献
论文
- O’Leary, K., Gleasure, R., O’Reilly, P., & Feller, J. (2020). Reviewing the contributing factors and benefits of distributed collaboration. Communications of the Association for Information Systems, 47, 476–520. https://doi.org/10.17705/1CAIS.04722
- 李玲,杨顺光. (2016). “全面二孩”政策与义务教育战略规划——基于未来 20 年义务教育学龄人口的预测. 教育研究,v.37;No.438, 22–31.
- 卢俊彪,张中太,唐子龙,& 郑子山. (2004). 一种新型的锂离子电池正极材料——LiFePO_4. 稀有金属材料与工程,07, 679–683.
- 谢宇. (2012). 社会学方法与定量研究. 社会科学文献出版社.
- 于春玲,郑晓明,孙燕军,赵平. (2004). 品牌信任结构维度的探索性研究. 南开管理评论 (02),35-40.
- 中国互联网络信息中心. (2020). 第 45 次中国互联网络发展状况统计报告. http://www.cnnic.cn/hlwfzyj/hlwxzbg/hlwtjbg/202004/P020210205505603631479.pdf
- 张苏秋,王夏歌. (2021). 媒介使用与社会资本积累:基于媒介效果视角. 国际新闻界,139–158. https://doi.org/10.13495/j.cnki.cjjc.2021.10.007
专著
- 社会研究中的统计应用
- 调查研究中的统计分析法
- 社会统计学
- 回归分析
- 问卷统计分析实务——SPSS 操作与应用
- SPSS 统计分析实用教程
- 量化研究与统计分析——SPSS 数据分析范例解析
- 行为科学统计精要(第 8 版)
- APA 格式:国际社会科学学术写作规范手册
- 菲利普·帕尔姆格林, 丽贝卡·B.鲁宾. 传播研究量表手册Ⅰ. 邓建国, 译. 上海: 复旦大学出版社, 2018.
手册
- SPSS 软件帮助文件
在线课程
THE END
更新日期:2023-11-06